Mercari Advent Calendar 2018 の14日目はメルペイ DataPlatform チームの @syu_cream がお送りします。
本記事では表題の通り、メルカリとメルペイにおける、マイクロサービスのログ収集に関する課題と取り組みについて記載します。
メルカリとメルペイでは、現在クライアントアプリやサーバサイドのログを効率的に収集してサービスの他機能で活用するための基盤の開発を共同で行っています。
メルカリ・メルペイ間では、一部提供するサービスの差異やデータ管理のポリシーの都合によりインフラ構成が異なる部分はありますが、少なくとも思想や設計、実装は共有しています。
これの具体的な内容については、今回の Advent Calendar の 3 日目の記事に掲載しています。
本記事では、サービスを提供するサーバサイドアプリケーションから、この構成図における “A Service Ramp” と呼ばれるデータパイプラインの入力に至るまでの道のりと技術選定の経緯、今後の課題などを取り上げます。
メルカリログ収集前史
まずはマイクロサービスに取り組み始める前のメルカリにおけるログ収集がどうなっていたか振り返ってみます。
マイクロサービスに移行する前のメルカリの機能群は、対称的なモノリスなサーバサイドの API 等と Android/iOS アプリ、 Web のフロントエンドから構成されます。
API 等という部分は紐解いていくと要件によって提示実行されるバッチ処理やイベントドリブンに処理を行うワーカなど多数の機能が存在します。
そして大部分の実装が単一のリポジトリで集約管理されています。
マイクロサービスの文脈で語るとモノリスは改善されるべき悪いもののように捉えられるケースもあるかも知れません。
しかし少なくともアクセスログやアプリケーションが都度出力するログなどサービスのログの収集観点で言うと、構成がシンプルであるため非常に効率的に行えます。
以前の記事で示したように、同一のコードベースで構築された、ある程度数が限られたサーバ群からそれ用にチューニングされたエージェントを用いてログを収集すればいいからです。
マイクロサービスの世界におけるログ収集はこれほどシンプルには済みません。
各マイクロサービスはそれぞれ異なるプログラミング言語、技術スタックで実装したアプリケーションを、個別のチームが Kubernetes 上に複数個からなる Pod という形で非同期にデプロイしていくからです。
マイクロサービスにおけるログ収集手段
この課題に対してメルペイでは開発当初から意識し始めており、 DataPlatform チームというデータの課題を解決する専門のチームを構築するに至っています。
この辺りの経緯や現在構築中の基盤システムは builderscon 2018 LT など多数の場所で既に周知済みです。
メルペイにおける、マイクロサービスに寄り添うログ収集基盤 – builderscon tokyo 2018
DataPlatform の基本思想は、多数に分散したマイクロサービスの世界からログを一箇所に集約して、必要なデータユーザに伝達するシステムです。
この思想は LinkedIn の Unified Log の構想などに通じるものがあると考えます。
基本的なオプション
Kubernetes 上でマイクロサービスを構築するにあたって、 Kubernetes の公式ドキュメントがいくつかのオプションを提示してくれています。
- ノードの Logging Agent を使う
- Logging Agent を持った Sidecar Container をアプリケーション Pod に含める
- ログ出力する Sidecar Container をアプリケーション Pod に含める。ログ送信は別 Pod が行う
- アプリケーションから直接ログ収集のバックエンドにログを送信する
ref. Logging Architecture – Kubernetes
これらのオプションはそれぞれトレードオフやログ収集に対して責任を負う人物が異なる格好になります。
例えば最初のノードの Logging Agent を用いる方針は他のオプションよりログ収集のためのインフラ構築のコストが安く、シンプルに済むと思われます。
しかしながらノードを運用する人物が Logging Agent のチューニングやモニタリングなど収集できることを担保し続けなければならなくなります。
またサービス毎にログの収集に対する要件が異なる場合でも共通の Logging Agent を用いてしまっている為に個別の要件への対応が難しくなるケースがあるかも知れません。
Sidecar Container を用いる方針はこのデメリットを緩和するかも知れません。
しかしながら各マイクロサービス担当者はアプリケーションの Pod に何らかのログ収集用コンテナを含めて運用しなければならず、組織としてログ収集に関わる運用コストが増大します。
アプリケーションのロジックで直接ログを送信するパターンは Kubernetes のドキュメントでは触れられていません。
このオプションはインフラレベルでログ収集を考えることを放棄してアプリケーションの実装だけで完結させる、ある意味シンプルでわかりやすい構成と言えそうです。
しかし Envoy Proxy の文脈で、共有ライブラリを開発・運用していくのを避けて Sidecar Container として動作する前提のプロキシが開発されたのを鑑みると、マッチしない組織も多いかと思われます。
またログ収集の支援をインフラレベルで行えないことがアプリケーションのロジックの複雑さを増長することに繋がる恐れもあります。
What is Envoy — envoy 1.9.0-dev-298dbf documentation
他社事例
マイクロサービスアーキテクチャに則った企業ではどのような手段を選んだのか確認してみましょう。
あらかじめここでは公表された記事から推測した部分もあり、現在のアーキテクチャに合致しているかどうかの正確性を保証していないことをお断りさせてください。
さて、私的なブログにまとめた例ですが、 Netflix では Java 実装の共有ライブラリを提供してログ収集基盤の入り口となる Kafka に投入していたようです。
(Non Java アプリケーションのためにプロキシもあるようです)
また Spotify は 2016 年の記事によると、マイクロサービスが出力するログを tail する Logging Agent とログを安全にバックエンドに届けるシステムを分離しているようです。
しかしこのやり方だけでなくログ収集用の API を直接マイクロサービスにアクセスさせる方針も許可しているようです。
(余談ですが Spotify のデータパイプラインについては 2018 年に発売開始した Google – Site Reliability Engineering の “The Site Reliability Workbook” という書籍に少し記載があります)
その他にも GKE (Google Kubernetes Engine) ではデフォルトで DaemonSet としてノードに蓄積されたログを Logging Agent で送信する仕組みを提供してくれていたりします。
これらが示す通り、ログ収集についての既存事例も決定的なアーキテクチャがあるという訳でなく、各社模索してそれぞれの組織や技術スタックにマッチした選択をしているように思えます。
メルペイのデータパイプラインの構成
翻ってメルカリ・メルペイではどうすべきなのかを考えます。
以降では特に、筆者の所属組織でありメルカリとは異なるペースでマイクロサービスをデプロイしていくメルペイに絞って記載していきます。
2018 年秋頃
メルペイで最初期に構築したログ収集の仕組みは、収集部分についてはシンプルに済ませました。その概要は下図の通りになります。

GKE ではデフォルトでは Stackdriver Logging をバックエンドとします。
DaemonSet として Stackdriver Logging にログを送信する用の fluentd が動作しており、各 Pod が出力した標準出力の内容をバッファして送信してくれます。
Logging Using Stackdriver – Kubernetes
この収集方法は GKE デフォルトの実績ある仕組みに乗れて、かつ各マイクロサービスは標準出力にさえログを出力しておけば良いので可搬性や共有ライブラリの導入などの障壁が無く良いものと言えました。
しかしながらログエントリが文字列型であることを強制される、サービスの成長によりデフォルトの fluentd DaemonSet では裁けず結局チューニングが必要になる、デバッグ用のログなどと出力が混ざる、 Stackdriver Logging という中間システムを介することによる信頼性やレイテンシの悪化など複数の問題が指摘され、別のオプションを模索することになりました。
現在
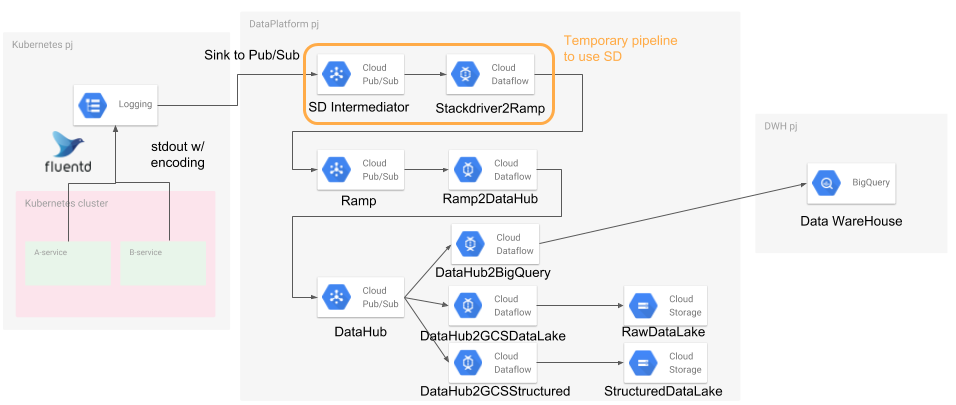
下図は現在のメルペイのログ収集の仕組みです。本記事執筆時点では完全に上図の構成から移行し切れてはいませんが、概ねこの図に従う形になっています。
現在の構成からは Stackdriver Logging は取り払っており、代わりに各マイクロサービスのアプリケーション実装から直接 Cloud Pub/Sub にログを送信する形になります。
Cloud Pub/Sub へのログ送信部分に関しては、現在メルペイでは Go 実装のマイクロサービスが多いことを考慮して Go 向け共有ライブラリの提供を行っています。

まとめと今後の課題
いかにしてマイクロサービスのログを収集するかの記事、いかがでしたでしょうか。
現在のメルペイのデータパイプラインですが、 Stackdriver Logging を介していた頃と比べて幾つかの問題は解決しているものの、一方可搬性や導入コスト低下のメリットを殺してしまっています。
この現在の構成が正解だと考えている訳でもなく、更によいログ収集の仕組みが無いかと模索し、トレードオフがあるならログを収集する対象のマイクロサービスが適したオプションを選べるようにするのが今後すべきことと捉えています。
明日 15 日目の執筆担当は @jollyjoester です。引き続きお楽しみください