こんにちは、メルペイのバックエンドエンジニアの @kazegusuri です。
2018年10月4日にMTC (Mercari Tech Conf) 2018 が開催されました。ご来場された皆様、楽しんでいただけたでしょうか?
今回は皆様が最初に目にしたであろうカンファレンスLPの裏側について紹介したいと思います。
実はこのページはGitHub上でPublicなリポジトリとして公開されています。
気づかれた方もいらっしゃるかもしれませんが、これはイベント後に公開したわけではなく、リポジトリ作成時からずっとPublicな状態で開発を続けていました。
チーム構成
MTC2018では最初からWebでの公開だけではなくカンファレンスアプリを作ろうというのを決めていました。
そのため大きく分けてwebチームとappチームに分けて開発をすすめることになりました。
web/appチームはメルカリグループから有志で集まって構成されています。
appチームについては後日ブログが公開されるのを期待するとして、ここではwebチームについて説明します。
webチームは4名のソフトウェアエンジニア+1名のデザイナーで構成されています(偶然全員がメルペイ!)。
- @kazegusuri: webチームリーダー兼インフラ, 雑用担当
- @sawa_zen: フロントエンド担当
- @vvakame: バックエンド担当
- @adwd118: 遊撃担当
- @akonyakayama: デザイン担当
このメンバーで業務としてカンファレンスLPの開発に取り組みました!
MTC2018 Webのコンセプト
こんなに素晴らしいソフトウェアエンジニアの方たちを集めたのも、今回のWebを作る際の最初のコンセプトが「ちょっとしたLPを本気で作ろう」ということからでした。
そのコンセプトから実際にチームメンバーの中で議論して「メルカリ・メルペイが実際に使っている技術を知ってもらおう」ということを決めました。
- 最初からPublicリポジトリとして公開
- GoとNode.jsを使ったサーバサイド実装
- CircleCI/SpinnakerによるCI/CD
- Kubernetes(GKE)によるコンテナ管理
- データストレージにCloud Spanner
ここから、今回のもうひとつのコンセプトである「面白い技術を使ってみよう」から、webチームとしては GraphQL を使うことにしてました。
GraphQLでフロントエンドやカンファレンスアプリ向けにAPIを提供します。
最終的にこの3つのコンセプトで開発を進めました。
- ちょっとしたLPを本気で作ろう
- メルカリ・メルペイが実際に使っている技術を知ってもらおう
- 面白い技術を使ってみよう
GoとNode.jsを使った開発の詳細については @vvakame と @sawa_zen にそれぞれおまかせするとして残りの部分について紹介したいと思います。
カンファレンスLPの構成
冒頭で述べたとおりソースコードは mtc2018-web リポジトリで公開されています。このリポジトリでNode.jsの実装とGoの実装の両方を管理しています。
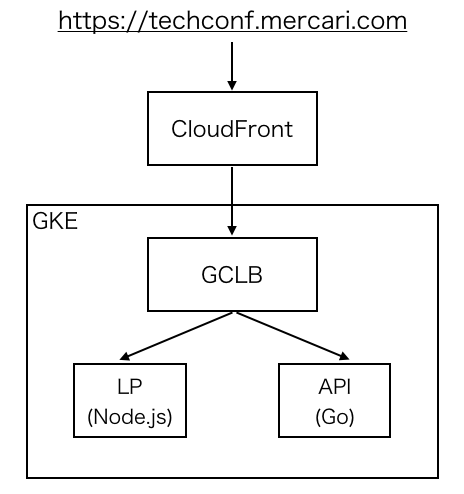
https://techconf.mercari.com |- /2017 (MTC2017のLP) |- /2018 (MTC2018のLP) |- /2018/api (MTC2018のAPI)

MTC2017とMTC2018のLPはNode.jsのサーバでリクエストを受けており、MTC2018のAPI(GraphQL)をGoのサーバでリクエストを受けています。ルーティングは GCLB(Google Cloud Load Balancing) で行っています。
GCLBの前段にはCDNとしてAmazon CloudFrontを利用しています。
CircleCI/SpinnakerによるCI/CD
メルカリ・メルペイでは現在はCircleCIによるCIが主流です。
社内のリポジトリではCircleCIの context 機能を使った共通のスクリプトなどが整備されていますが、今回はそれらを使わずに単純なJobを複数組み合わせてworkflowを作っています。
mtc2018-web リポジトリでは1つのリポジトリでNode.jsの実装とGoの実装を含んでいるので、Jobもそれぞれでわけてtestやlintなどを実行しています。
それらのJobが成功したあとにdeployのJobで Google Cloud Build を使ってDockerイメージのビルドと GCR(Google Container Registry) へのイメージのアップロードを行っています。
DockerイメージをGCRにアップロードしたあとはCDとしてSpinnakerを利用しています。Spinnakerはデプロイパイプラインを定義できるツールです。
メルカリ・メルペイでは共通のSpinnakerクラスタを使っており、GCRへのアップロードをトリガーとしてKubernetesへのデプロイしています。
mtc2018-web リポジトリではdevelopタグがついているイメージは開発環境へ、masterタグがついているイメージは本番環境へデプロイするようにパイプラインを定義しています。GitHub上でマージするだけで各環境へのデプロイが自動化されています。
Kubernetes(GKE)によるコンテナ管理
メルカリ・メルペイではメルカリの Microservice Platform Team が管理するKubernetes環境を共通で利用しています。
今回のカンファレンスLPも共通の環境を利用して開発環境と本番環境を提供しています。
GCLBはGKEのIngressを使って構築されています。
こちらは実際に適用しているIngressの設定を一部変更したものです。
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: mtc2018 namespace: mtc2018 annotations: kubernetes.io/ingress.global-static-ip-name: "mtc2018" kubernetes.io/ingress.class: "gce" spec: tls: - secretName: tls-mtc2018 hosts: - mtc2018.xxx.com rules: - host: mtc2018.xxx.com http: paths: - path: "/2018/api/*" backend: serviceName: mtc2018-api servicePort: 80 - path: "/*" backend: serviceName: mtc2018-web servicePort: 80
- cert-manager によるSSL証明書の発行
- external-dns によるDNSの設定
- pathによるAPIとLPのエンドポイントでのルーティング
これで同じnamespace内に mtc2018-api と mtc2018-web という Serviceを用意して、それぞれAPIとLPのPodを管理をしています。
データストレージにCloud Spanner
メルペイではほとんどすべてのマイクロサービスでCloud Spannerをメインのデータベースとして利用しています。
カンファレンスLPでもとりあえずSpannerを使って何か作ろうと考えていました。
しかし残念ながら時間が足りずに最終的にオミットした機能がLike機能です。
セッション毎にLikeを何回でも押せて、他人のLikeもリアルタイムに自分の画面に反映されるような企画を考えていました。
バックエンド側はほとんど機能的には完成しており、その実装でSpannerを利用しています。
ここではSpannerを使ったLike機能の実装について詳細に紹介したいと思います。
Like機能
Like機能の仕様としては以下の通りです。
- 特定のセッションに対してLikeできる
- Likeは何回でもできる
- あとから集計できるようにLikeはすべて保存する
- ログインがないのでユーザーのユニーク性はクライアント側でなんとかする
- 他のユーザーが押したLikeをリアルタイムを受け取ることができる
大きくわけると機能的には、保存部分とそれに応じたPub/Sub部分にわけることができます。
保存部分
基本的にデータベースにInsertするだけなので難しくはないのですが、
Likeをユーザーの気分に応じて思いっきり連打できるようにしたかったのでスケーラビリティをどこまで考えるかが課題となります。
今回は結局特に目標値を事前に決めたりはしなかったのですが、できる限りいいかんじの実装を作ってそれで満足するという方向性にしました。
Likeはすべて保存する必要があるという要件から、時刻などの順序性があるものをPrimary KeyにすることはSpannerの特性上避けたかったので、単純にUUIDをキーとして保存するというスキーマにしました。リアルタイムの参照の要件がなかったので、集計用途だけならGoogle BigQueryにいれたら良いと考えたからです。
CREATE TABLE Likes ( Uuid STRING(64) NOT NULL, SessionId INT64 NOT NULL, UserUUID STRING(64) NOT NULL, CreatedAt TIMESTAMP NOT NULL, ) PRIMARY KEY(Uuid);
Spannerの書き込みはGCE(Google Compute Engine)からリクエストする分には十分早い(~100ms)のとUUIDがPrimary Keyにしたことで十分にスケールするので単純にLikeのリクエスト毎に保存しても問題ない気がしますが、気づいたらこの書き込み部分も最適化していました。書き込みを非同期にしてバッチ処理的に書き込みを行うというアイデアは初めからあったのと pvpool のことも知っていたので、似たような実装方針で進めました。
- Likeのリクエストでは構造体をインメモリの配列に入れるだけでレスポンスを返す
- goroutineで定期的に配列の中身をSpannerに保存する
前者は特に難しくないので割愛しますが、後者の実装はこんな感じです。
func (s *storer) Run() { ticker := time.NewTicker(time.Second) defer ticker.Stop() done := false for { select { case <-s.done: done = true break case <-ticker.C: } if done { break } go s.flushLikes() // 1秒に1回goroutineで書き込み処理 } } func (s *storer) flushLikes() { // 配列のロックを取ってコピーする s.likesMu.Lock() likes := make([]domains.Like, len(s.likes)) copy(likes, s.likes) s.likes = s.likes[:0] s.likesMu.Unlock() // 書き込み処理全体のタイムアウト parentCtx, cancel := context.WithTimeout(context.Background(), flushHardTimeout) defer cancel() for { select { case <-parentCtx.Done(): return default: } err := func() error { // 書き込みタイムアウト ctx, cancel := context.WithTimeout(parentCtx, flushTimeout) defer cancel() // LikeをSpannerに保存 _, err := s.likeRepo.BulkInsert(ctx, likes) return err }() if err == nil { return } } }
細かいところを考えると課題は残っていますが意識したところとしては
- flushLikes() 自体もgoroutineにして後続処理が詰まらないようにする
- Spannerに問題があったときにgoroutineが無限に増えないように flushLikes() 全体にタイムアウトをつける
- Spannerの接続にたまたま問題があったときにリトライできるように書き込み処理単体にもタイムアウトをつける
Pub/Sub部分
Pub/Subをどうやって実現するかが一番難しい問題です。Redisがあれば楽なのですが 用意するのが面倒 Spannerでなんとしてもやるぞという強い気持ちで頑張ることにしました。
Spanner自体に書き込みをイベントとして受け取るような機能はないので自力で作ることにしました。基本のアイデアとしては各サーバーでgoroutineを動かしておいて、定期的にテーブルを見て更新があったら通知するというものです。
Likesの保存でもともと非同期で書き込み処理を行う部分ができていたので、Pub/Sub処理を3つの処理に分けることにしました。
- storer: Likeの保存とLikeイベント用データの保存
- observer: Likeイベント用データの新規書き込みの検知
- listener: subscriptionしているユーザーへの通知
Likeの保存用テーブルはUUIDをPrimary Keyにしてしまったことと書き込み頻度が多くて単純に保存時刻にインデックスを貼ることはできないことから、あとでobserverがLikeの書き込みを検知する目的には利用できません。
よって、Likeの保存とは別にイベント用データを作ってそれをobserverが検知する方針にしました。
そもそも通知のリアルタイム性をどこまで求めるかという要件次第で設計が変わってきます。
今回はざっくりと1,2秒くらいなら良いだろうということを勝手に決めて、1秒毎のLike数を通知することにしました。
Like数分個別に通知することもできますが、おそらくトラフィック的にも無駄が多そうなので、数を渡してフロントエンド側で頑張ってくださいということにしました。
これら要件からイベント用データの保存の方針は
- 1秒毎にその期間中のLikeのカウントを保存する
- セッション毎に保存する
- サーバ毎に保存する
イベント用のテーブルはこのようになりました。
CREATE TABLE LikeSummaryServers ( Second INT64 NOT NULL, SessionId INT64 NOT NULL, ServerId STRING(64) NOT NULL, Likes INT64 NOT NULL, CreatedAt TIMESTAMP NOT NULL, ) PRIMARY KEY(Second, SessionId, ServerId);
時刻をPrimary KeyにもってくるというSpannerに悪い設計ですが、1秒毎にセッション数×サーバー数しか書き込まないテーブルなのでSpannerに頑張って欲しいということで諦めました。
実際のところはobserverのクエリを頑張ればインデックスの順番を変えられます。
observerはこのテーブルから特定の時刻(Second)を指定してLikesのSUMをとればすべてのサーバのLikeの合計値を取得できます。
さて、ここからこの実装方針の 地獄 課題の始まりです。
storerは1秒ごとに自身のServerIdに対応するレコードを保存するのですが、きっちり時間通りにレコードが保存される保証がないのが問題です。
全てのサーバがきっちり000msから書き込み処理を開始してくれて、999msまでに書き込みを完了してくれたら良いのですが、以下の理由で難しいです。
- 時刻の制御をきっちり行うのは難しい
- Spannerの書き込みに時間かかる可能性がある
- そもそもサーバ間の時刻が完全に同期されているわけではない
つまり該当期間(Second)のイベントデータの書き込みが数秒後に現れる可能性があります。
なのでobserverは単純に直前の期間(Second)だけのデータを見ると実際の合計数と大きくずれる可能性がでてきます。
observerの方針を少し変えて、直近n秒間の期間毎のSUMを取って変化を見るということにしました。
これを具体的な例で解説すると
Time --------------------------> 1003 1004 1005 1006 Second 1005: 1 1004: 2 2 1003: 1 5 5 1002: 0 2 3 x 1001: 2 2 x x 1000: 1 x x x Increase: +3 +3 +7 +1
これは直近3秒間で見た場合ですが、1003秒の時点で1000,1001,1002のSUMはそれぞれ1,2,0だとすると、次の1004秒の時点で見る1003,1002,1001が2,2,1なのでそれぞれの期間ごとの増加は0,2,1となり合計で+3となります。これがobserverが観測した1004秒におけるLike数の合計値とします。
listenerはGraphQLのSubscriptionを行っているクライアントの管理をしていています。
observerが観測したLike数の変化をchannelで受け取って、各クライアントにPublishするのが責務です。
このあたりはそれほど複雑なことをしていない(observerと比較して)ので割愛します。
これらのstorer, observer, listenerの実装は こちら においてあります。
2,3日でえいやと作って、ちゃんとした検証もできているわけではないので大小バグが残っていますがだいたい意図通り動いています。
Yo
Yoはメルカリ社内で試行錯誤中のSpanner用ライブラリです。メルペイのプロジェクトの多くがYoを使って開発されています。
イベント当日までにはOSSにするぞという意気込みでパブリックに使い始めたのですがまだ整備中です。乞うご期待ください!
おわりに
まだまだ OpenCensus を使ったモニタリングの設定など細かいところで試してみたことがありますが、「本気でLPを作る」には足りていないところが多く残ったままとなりました。
最近はカンファレンスサイトを作るのが好きな人という謎の称号を手に入れましたが、次回はもっと本気で挑戦したいと思います!
メルカリ・メルペイでは業務としてカンファレンス運営を手伝っています。次回に向けてカンファレンスサイトを「本気で」作りたい方も募集しています!
次回は @vvakame が API で利用した GraphQL 部分について解説してくれると期待!



