最近、SRE になった @b4b4r07 です。今回は、直近のタスクだった社内アプリを Kubernetes に載せ替えた話をします。
前置き
メルカリでは全社的 1 に Crowi という Markdown で書ける Wiki アプリケーションをナレッジベースとして採用しています。
以前は、プロダクトチームは Qiita:Team、コーポレート系は Google Sites と言った具合に、各部署ごとに異なるドキュメントツールを使っていました。これではよくないと、エンジニアに限らず誰でも書きやすく参照しやすい Wiki のようなサービスが必要とされ、Crowi の採用に至りました。
まずはみんなに使ってもらうために広めていこうと、試験的に導入が始まったため、今回の移行話までは 1 台の EC2 インスタンスにアプリケーションサーバと Nginx、MongoDB が動いていました。全社的に浸透し、Crowi 導入から 1 年が経った頃、社内ナレッジベースとしての重要性が日々増していく中、そのインフラ (構成とデータのバックアップなど) を見直そうという動きになりました。
そして今年の夏に SRE チームへの異動となった私がその初仕事として、社内ツールとして動いていた Crowi の構成と運用の見直しをすることになりました。
本記事では、Crowi を Kubernetes 上で動かす方法と、その載せ替えの際に得た経験についてまとめます。これについては、Crowi に限った話ではなく、一般化して広く「Web アプリケーション」を Kubernetes で動かすためにも活かせる知見だと思います。
本題
移行前の問題点と目標
- EC2 インスタンス 1 台で運用している → スケールさせられるようにしておきたい
- 記事 (MongoDB) のバックアップは cron によるダンプのみ → DB のレプリケーションを用意したい
- 運用方法が定まっていなかった → デプロイや問題が発生したときのロールバックをハンドリングしたい
これらの課題を包括的に解決するために、アプリケーションを Docker 化して Kubernetes を使ったスケール & スケジューリング管理をするのがよいと判断しました。また、Kubernetes のプラットフォームとして Google Container Engine (GKE) を採用しました 2。
構成
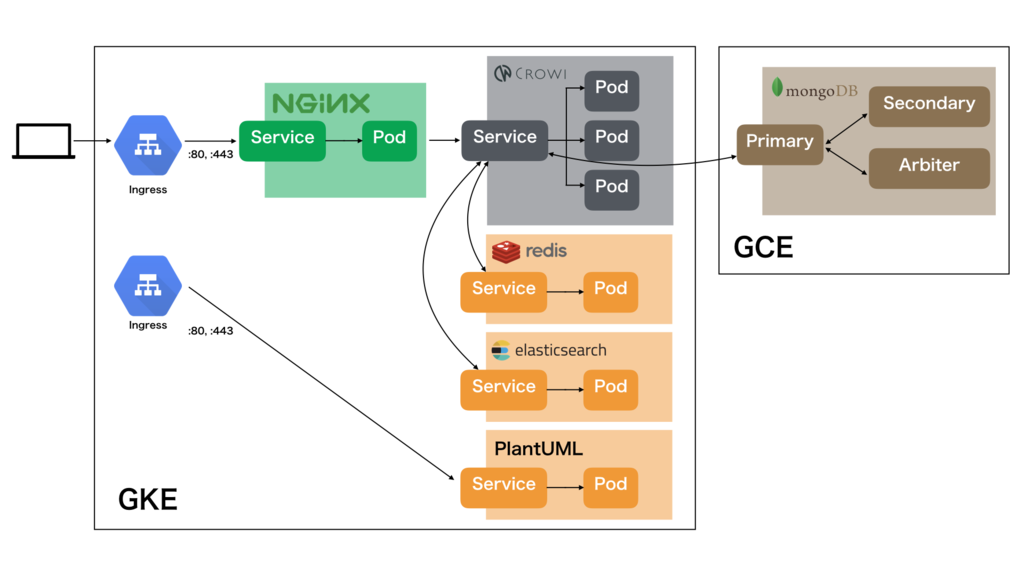
Crowi では以下のミドルウェアを使用しています。これらステートレスなアプリケーションは Docker 化して Crowi と同じように扱うことができます。
- Elasticsearch: 記事の検索
- Redis: セッション情報のキャッシュ
- PlantUML: UML 記法のレンダリング
データストアである MongoDB は Kubernetes の外に出し、Google Compute Engine (GCE) のインスタンスにサーバを立てました3。また、今回は MongoDB の Replica Set を使ってレプリケーションを行うため、3 台のインスタンスを用意しました。
- MongoDB: データベース
以上を踏まえ、最終的な構成図は以下のようになりました。Google Cloud Load Balancer (GCLB; Ingress) とアプリの間にいる Nginx については後述します。

移行する
移行までのステップは以下の通りです。
- GCP に専用プロジェクトを作り、GKE に Kubernetes クラスタを作る
- Crowi の Dockerfile を書く (Redis などはオフィシャルのもの使うので不要)
- 各種 Kubernetes の Object を書く
- Object を Kuberntes クラスタにデプロイする
- MongoDB 用のインスタンスを用意する
- レプリケーションを作成する
- Crowi と各種ミドルウェアをつなぐ
- Crowi Pod を Rolling Update する (Database connection error が解決しつながるようになる)
- 本番を一時止め、データのマイグレーションを行い、DNS の切り替えを行う
では、それぞれについて詳細にみてみます。
まずは、GKE 上に Kubernetes クラスタを作成します。これは gcloud コマンドから行ったほうがよいです。どのような設定が反映されたクラスタなのか、GUI を見るよりそのコマンドを見るほうが把握しやすいからです。
$ gcloud alpha container clusters create ${CLUSTER}
--project="${PROJECT_ID}"
--zone="${ZONE}"
--machine-type=n1-standard-8
--scopes=default,storage-rw,bigquery,sql-admin,datastore,logging-write,monitoring-write
--enable-autoscaling
--max-nodes=20
--min-nodes=1
--enable-cloud-logging
--enable-cloud-monitoring
Redis、Elasticsearch、PlantUML は特にカスタマイズする必要がなかったので、Docker Hub にてオフィシャルでホスティングされているものを使用しました。Crowi については Dockerfile を書き、Google Cloud Registry (GCR) に Push しておきます。
次に Kubernetes に Object をデプロイするための準備として、YAML ファイルを書いていきます。
Kubernetes は Pod という単位でコンテナ (Docker コンテナなど) を括り、それらを Node (VM やインスタンスに相当する概念) にスケジューリングします。各 Pod は Kubernetes の機能である Auto-healing などで停止する可能性があり、再生成されるときにどの Node にスケジューリングされるかわかりません。ゆえに正しく Service Discovery するために Service というリソース (Load Balancer のようなもの) でまとめておくことが通例です。それらのデプロイを Deployment というリソースで管理することで、Pod の Rolling Update などを制御することができます。クラスタ (例えば Crowi という Service)を外部に公開するには、Ingress というリソースを用います。それらの設定を Kubernetes Object として YAML (JSON) 形式で記述します。
$ tree . ├── crowi.yaml ├── elasticsearch.yaml ├── ingress.yaml ├── nginx.yaml ├── plantuml.yaml └── redis.yaml 0 directories, 6 files
Crowi の場合は Crowi (app.js) と PlantUML の Ingress を用意します4。ingress.yaml を除くそれぞれの YAML ファイルにそれぞれの Deployment、Service を書いています。詳しい書き方は公式ドキュメントを参照してください。
--- apiVersion: v1 kind: Service metadata: labels: app: crowi name: crowi-service spec: ports: - protocol: TCP port: 3000 targetPort: 3000 type: NodePort selector: app: crowi tier: backend --- apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: app: crowi name: crowi ...
次に MongoDB のレプリケーションの設定についてです。GCE にインスタンスを 3 つ用意します。
- Primary
- Secondary
- Arbiter
Arbiter は昇格用インスタンスではないのでパワーは必要ありません。インスタンスのセットアップは Terraform で、プロビジョニングは Ansible で行いました。
詳しくは以下のマニュアルが参考になります。
GCE のインスタンスはその GCP 内で有効な内部 DNS が自動で振られています。
hostName.c.[PROJECT_ID].internal
https://cloud.google.com/compute/docs/vpc/internal-dns
これを使って Primary の MongoDB インスタンスのアドレスを Crowi に教えてあげるとデータベースへ接続することができます。
また、Redis や Elasticsearch といった Service もその Kubernetes 内で有効な内部 DNS が自動で振られています。これは他の Pod の中から nslookup して、その Service に振られている内部 IP アドレスを引くことで確認できます。
$ kubectl describe svc redis-service Name: redis-service Namespace: default ... Port: <unset> 6379/TCP ... $ kubectl exec -it POD nslookup redis-service.default.svc.cluster.local Name: redis-service.default.svc.cluster.local Address 1: 10.15.251.10 redis-service.default.svc.cluster.local
https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/
これらの必要な情報を環境変数に設定し、Crowi の Pod を Rolling Update しましょう。env に書きづらいパスワードのシード値といったものなどは Secret 経由で渡すと良いでしょう。
env: - name: MONGO_URI value: mongo-1.c.mercari-wiki.internal:27017/crowi - name: REDIS_URL value: http://redis-service.default.svc.cluster.local:6379 - name: ELASTICSEARCH_URI value: http://elasticsearch-service.default.svc.cluster.local:9200
これにて、サービスが動くようになるので本番のデータをマイグレーションし、DNS の切り替えを持って移行の完了です。
移行後
移行前に挙げた課題と目標は以下のように達成されました。
- EC2 インスタンス 1 台で運用している → スケールさせられるようにしておきたい → Kubernetes のオートスケール、MongoDB の Replica Set を使った自動フェイルオーバー
- 記事 (MongoDB) のバックアップは cron によるダンプのみ → DB のレプリケーションを用意したい → レプリケーションによる冗長化、ホットスタンバイ
- 運用方法が定まっていなかった → デプロイや問題が発生したときのロールバックをハンドリングしたい → Docker イメージにしてバージョニング、Kubernetes によるデプロイ
移行から 1 ヶ月以上経ちましたが、今のところ問題なく稼働しています。
ハマリポイント
今回の移行を経て実際にハマったポイントを、後学の「Kubernetes 上で Web アプリケーションを動かすときにハマりそうな点」としてまとめます。
Ingress の Health checks について
現在の仕様では、すべてのバックエンド Service は、GCE ロードバランサから送信された HTTP(S) ヘルスチェックのために、次のいずれかの要件を満たす必要があります。
/で 200 を返すかどうか- readiness probe として公開されたバックエンド Service の任意のエンドポイントが 200 を返すかどうか
Ingress のコントローラはまずはじめに readiness probe を見に行きます。設定があれば、そこのエンドポイントに対して GCE ロードバランサから HTTP(S) のヘルスチェックが行われます。readiness probe がない場合は、GCE ロードバランサは / に対して HTTP(S) ヘルスチェックを行います。
つまり、バックエンドサービスのヘルスチェック用のエンドポイントに対して readiness probe を設定しないと、/ に対して 200 を返すかどうかのチェックが走るわけです。すべてのサービスが必ずしも / で 200 を返すかどうかはわかりません。例えば、/ でリダイレクトが実行される場合 (セッション情報がないクライアントは / -> /login のリダイレクトにより 302 を返す) などはヘルスチェックに失敗します。
うっかりハマりがちなので、正しくヘルスチェック用の readiness probe を設定することが推奨されます。
readinessProbe: httpGet: path: "/_api/healthcheck" port: 3000
これについて、詳しくは公式の README にあります。
https://github.com/kubernetes/ingress/tree/master/controllers/gce#health-checks
Ingress での HSTS 設定
Ingress は、インバウンドな接続を許容するために使用され、サービスを外部から到達可能な URL にしたり、トラフィックの負荷を分散したり、SSL ターミネーションをしたりすることができます。そして、Ingress コントローラは通常、ロードバランサを使用して Ingress を実行します。
これらの設定に metadata.annotations が使われるのですが、どうやら HTTP Strict Transport Security (HSTS) ないしは HTTPS への Force redirect についてはできないようです。
https://github.com/kubernetes/ingress/blob/master/docs/annotations.md
GCP サポートに問い合わせたところ、現在 Ingress の GCE コントローラでの HSTS の設定はできないようで、自分のアプリケーションや別途立てた Nginx でリダイレクトするべきといった返答をもらいました。
よって、今回は Ingress と Backend Service の間に Nginx 用の Service を挟むことで HTTPS へのリダイレクトを設定しました。
location / { if ($http_x_forwarded_proto != "https") { return 301 https://$host$request_uri; } proxy_pass http://crowi-service.default.svc.cluster.local:3000; }
https://github.com/kubernetes/ingress/tree/master/controllers/gce#redirecting-http-to-https
Ingress で Nginx Service を Backend Service として設定し、nginx.conf で Crowi Service へプロキシしてあげます。また、同じクラスタネットワーク内にいるため、Service への内部 DNS が有効です。
まとめ
本記事では、Crowi という Wiki サービスを Kubernetes 上で動かす方法と、そこで得た経験やポイントなどをまとめました。
最近のメルカリでは Microservices 化を推進しています。Microservices として切り出せそうなものについては切り出され、徐々にプロダクションに投入されています。Mercari Wiki (社内ツールとしての Crowi) もその流れを汲み、同じ技術スタックを用いました。これはまだメルカリ社内には Crowi の開発チームがなく SRE で一部運用する目的も含んでいるためです5。
これを読んで、フルタイムで Crowi を開発してみたい方や、Kubernetes によるサービス基盤開発などに興味のある方はぜひ応募してみてください。