
Merpay & Mercoin Tech Fest 2023 は、事業との関わりから技術への興味を深め、Productやサービスを支えるエンジニアリングを知ることができるお祭りで、2023年8月22日(火)からの3日間、開催しました。セッションでは、事業を支える組織・技術・課題などへの試行錯誤やアプローチを紹介していきました。
この記事は、「Merpay & MercoinにおけるLLM活用の取り組み」の書き起こしです。
@nu2:みなさん、こんにちは。早速ですが、「Merpay & MercoinにおけるLLM活用の取り組み」についてセッションを始めます。現在、世界中のFintech企業も何かしらの投資対象として注目している。LLM技術について、メルカリグループで取り組んでいる内容をお伝えするセッションです。
Merpay & Mercoin Tech Fest 2023の最大の見どころの一つと言っても過言ではないと私は思っていて、非常に楽しみです。昨日もちょうどGoogle Cloud様が、LLM withビジョンという、テキストメッセージに対して、画像検索の形で応答するデモを公開されていまして、これはメルカリの学習データを提供して実現しており、タイムリーな話題になっています。

まずは自己紹介です。私は@nu2と申します。本日は、進行役を務めます。
私は5月に入社するまで、15年ほどWeb検索の領域に関わってきましたので、ここまでLLMが飛躍的な進化を遂げるとは正直思っていませんでした。今回はメルカリからVP of Generative AI/LLMの@mazeさんをお招きしておりますので、ディープダイブした内容を伺いできればと思います。
@maze:こんにちは、メルカリの@mazeです。現在は生成AIの担当役員をやっています。直近では、ソウゾウの代表をやっていました。今は120%生成AI関連にコミットしています。ソウゾウ立ち上げ前はメルペイにおり、メルペイの立ち上げや、金融の与信周りに携わっていました。今日はよろしくお願いします。
@tori:みなさま、はじめましてよろしくお願いします。Torigoeと申します。私は、2018年にメルペイに機械学習エンジニアとして入りまして、あと払いや不正対策の機械学習の応用に携わりました。メルペイの機械学習全体のマネージャーと、LLMや新しい技術を使って価値を出すチームのマネージャーも兼任しています。
今日は半年くらいいろいろ取り組んできたお話の経験を基にできるだけ楽しくお話できればと思います。よろしくお願いします。

@maze:まず、簡単にメルカリグループ全体の生成AIの取り組みを紹介します。

今年の5月にメルカリで生成AI/LLM専任チームを作りました。

ミッションとしては二つあります。生成LLMの技術を用いて、新しくお客さま体験を作ることと、それによる事業インパクトの最大化を一つ目のミッションとしています。
二つ目のミッションは、メルカリグループ全体として2000人以上従業員がいるのですが、従業員の生産性を劇的に上げることです。なるべく専任チームを作って、機動的に動ける形にしています。

チームでは、EnablingとBuildingの二つを掲げて進めています。
生成AIの技術は特定のチームに閉じるべきじゃないと思います。できればメルカリの従業員2000人全員が、十分に使えるという状態にしていければなと思いますので、なるべく推進できるようにする活動も僕らのチームとしてEnablingとしてやっています。
もう一つ、僕らはなるべくものを作れるチームで、Buildingでやっております。

Enablingについて、具体的にやっていることとしてまず挙げられるのが、ガイドライン策定です。
メルカリはこれまでもずっとAIに投資していまして、MLエンジニアも多数在籍しています。生成AIはAIの民主化的側面もあり、一般のソフトウェアエンジニアの方でも、気軽に触れるようになったと思います。皆さんが安心してAI開発できるように、各所と連携しながらガイドラインを作っています。
また、みんな「気になっているけれど忙しい」ということもあるので、ハッカソンの機会を作っています。3ヶ月おきに開催しており、頻度は高いです。

次はBuildingの一例です。僕がチームで初めに行ったのが、メルカリ社員専用のChatGPTを作ることです。Open AI社のChatGPTは、入力した情報が学習に使われてしまうので、メルカリ社員専用の業務内容を入れてもいいChatGPTを作りました。
それだけでは面白みがないので、メルカリ社員であれば無料でGPT4が使えたり、Googleのモデルにも対応していまして、同じプロンプトで出力がどう変わるかも試していただける形で作っております。

僕らが今注力したのはこちらで、既存のプロダクトにLLMを入れていくことに注力しています。グループ全体として、いろいろなFunctionチームがあり、そこと連携しながら、プロダクト開発を進めています。

進め方は、僕らLLMチームが企画から実装まで全部行うパターンと、各種Functionチームにリードをお願いして、プロンプト周りやどのモデル・ツールを使うのかといった細かい相談のみこちらで対応するパターンの2つがあります。
メルカリには、MLエンジニアを持っているチームも多数あるので、その場合は2つ目の「共創」のパターンで、発見を共有し合いながら進めていきます。

施策内容としては、既存プロダクトへの適用だけでもかなり幅が広いです。Fintechとまとめて書いていますが、いろいろな使われ方があります。それ以外に社内ツールの実装や、生成AIを生かして新規事業を考えることも含めていろいろ試しています。

生成AIの専任チームなので、技術の探索もあわせて行っています。モデルの選定について、ビッグテックが出しているLLMのAPIをどう使うのかという話や、OSSのモデルを利用するという話をしています。内製の基盤モデルを作るのも、選択肢としては一応あると思います。

LLMの進展に伴い、非常にいろいろなツールが充実しています。
実際にでてきたら触って、それがどう生かせるかを考えています。毎日何か新しいものが出てくるので、いろいろ試しつつ、メルカリではすぐにプロダクトに活かして、実際に本番環境でどうなるかを見れる、フィードバックをもらえるので面白いと思います。

@nu2:実際にSlackでドックフーディングのように、エンジニアの方たちがいろいろいじったり触ったりしているのを側から見ていて、本当にすごいなと思います。一方でFintechにおけるLLMの導入を進めかたは、メルカリとは違うところがあるのですが、@toriさん、いかがでしょうか。
@tori:Fintechでは、最初にLLMの波がきたときに、当然MLエンジニアが、各々独自に探索する動きはあったのですが、途中で専門でフォーカスしないと世の中に遅れてしまうなと思い、@mazeさんとほぼ同じタイミングで専門チームを立ち上げました。
それ以降、最初の3ヶ月間は、2つのアプローチを取りました。エンジニア自身が企画も含めて考えて、PoCするというアプローチと、MLエンジニアだけだと、どう使えばいいのかが悩ましかったので、LLMを使ったコンテスト(ぐげん会議)を行い、社内のいろいろな人のアイディアを借りるアプローチです。
最初は技術をキャッチアップしながら、どういう使い方をするのかをエンジニアがボトムアップで考えつつ、皆さんのアイディアも借りながら会社全体でどれがいいかを考えてきたところです。
ぐげん会議には、@nu2さんにも出ていただきました。
参考記事:LLMを活用してなにがつくれるか?——「ぐげん会議」開催から見えてきた、AI活用の新たな可能性
@nu2:ぐげん会議や、実用化を目的としたハッカソンを開催されていましたが、実用化したユースケースはありますか。
@tori:今まさにいろいろ仕込み中ですが、新しくPoCして取り組んで、結果としてそれをぐげん会議に出して、入賞したというユースケースがあるので、それについてチームメンバーからプレゼンテーションを用意しているので、ご覧ください。

@hmj:今回はLLMを活用した文章構成の取り組みについて発表します。

私は、@hmjといいます。株式会社メルペイで、機械学習を担当しております。
2018年より株式会社メルペイにて機械学習や、自然言語処理を中心とした与信モデルの設計開発を行い、その後不正検知の領域の機械学習のモデルや、システム開発に携わっていました。2023年4月より、LLMなどの新しい技術をキャッチアップするチームに所属しており、こういった取り組みをしております。今回はこちらの取り組みを紹介します。どうぞよろしくお願いします。

本日のアジェンダはこちらです。初めに概要を紹介し、その後課題や解決策の話をし、最後にツールの紹介と、簡単にまとめをしたいと思います。

では、はじめて行きたいと思います。
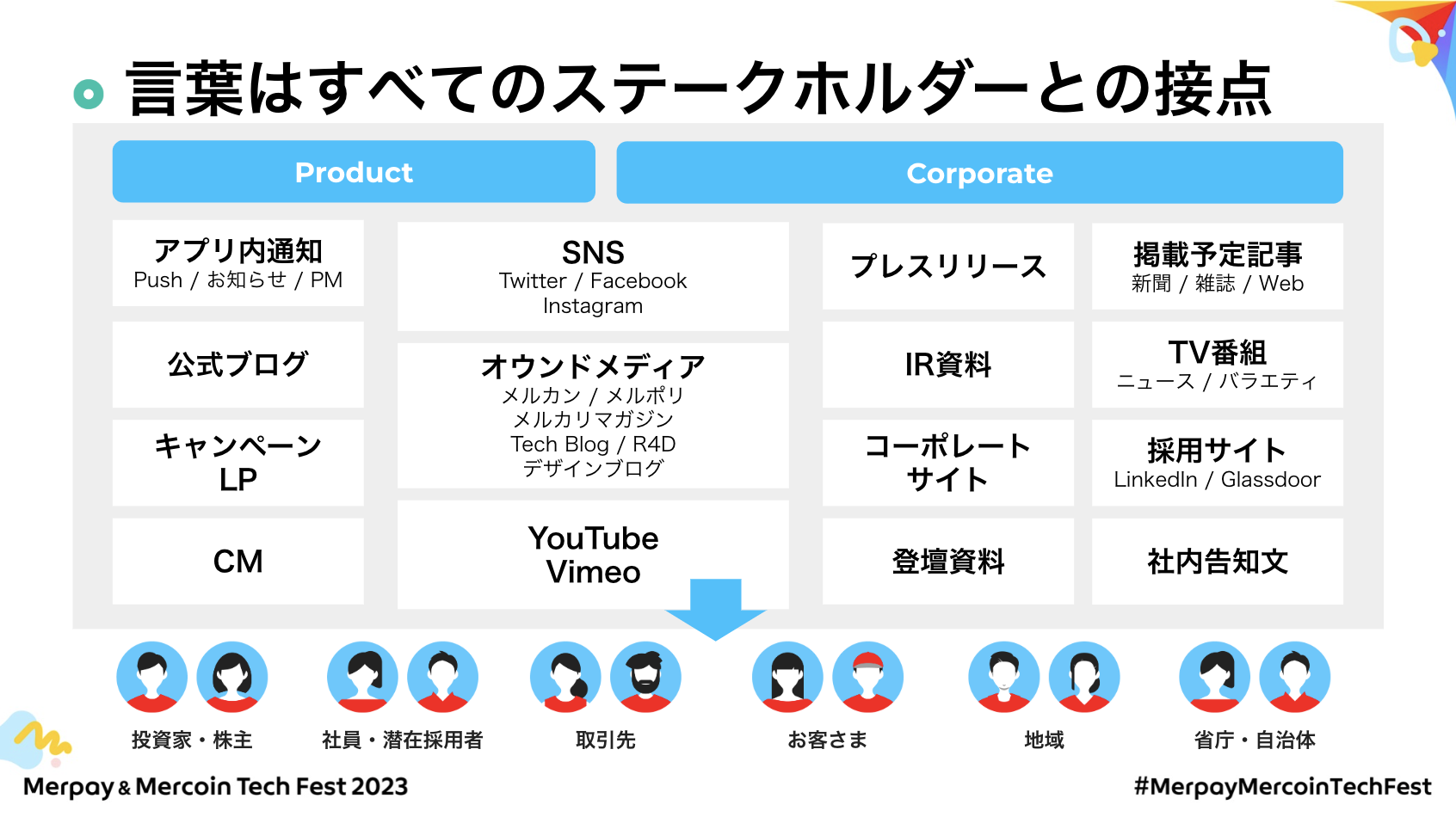
まずメルカリではステークホルダーの方とのタッチポイントがこの図の形でいっぱいあります。例えばお客さまに対するアプリ内での通知やキャンペーン情報、CMなどで日常的に多くの場所でメルカリに関する言葉が届けられます。
コーポレートやプロダクトの枠を超えて、数々のメディアや、アプリ内のお知らせでそういったタッチポイントが多くあるのでとても言葉には影響力があります。
そのため、社内の文章であってもしっかりとしたワーディングに関するチェックがとても大事になってきて、チェックをする仕組みが必要になってきます。
今回は文章校正チェックにLLMを活用できないかということでツールの開発を行いました。今回はそちらの取り組みについて紹介したいと思います。

では実際に課題感と、どう解決したかをご紹介したいと思います。

解決したい課題の一つは、ワーディングルールが全ての方に浸透していなくて、活用できないという場面があることです。また二つ目としては、チェックをしてワーディングルールを見ながら行うんですけど、非常に数や量が多くて、人の手でチェックをするのに限界があるということです。そこで求められていたのは、誰でも簡単に短時間でチェックを行える仕組みです。

その中で今回機能として求められていたのは、このようなところにあります。単純に校正した文章を出して終わりではなくてこの三つが求められていることが、社内議論する中で見えてきました。
一つ目は、指摘箇所が文章中でわかるようにすること。文書の中で、どの部分がチェックに該当するのかがわかるようにしたいということです。二つ目は、指摘の理由がわかるようにすること。ある言葉がチェック入ったときに、それがなぜチェックされているのかがわかるように、どのワーディングルールに該当するかを利用者にわかるようにしたいということです。最後に、指摘をして修正した文章を、アウトプットとして取得できるようにしたいということがありました。

続いて、求められていることについて、どういった社内ツールを作ったかをご紹介します。
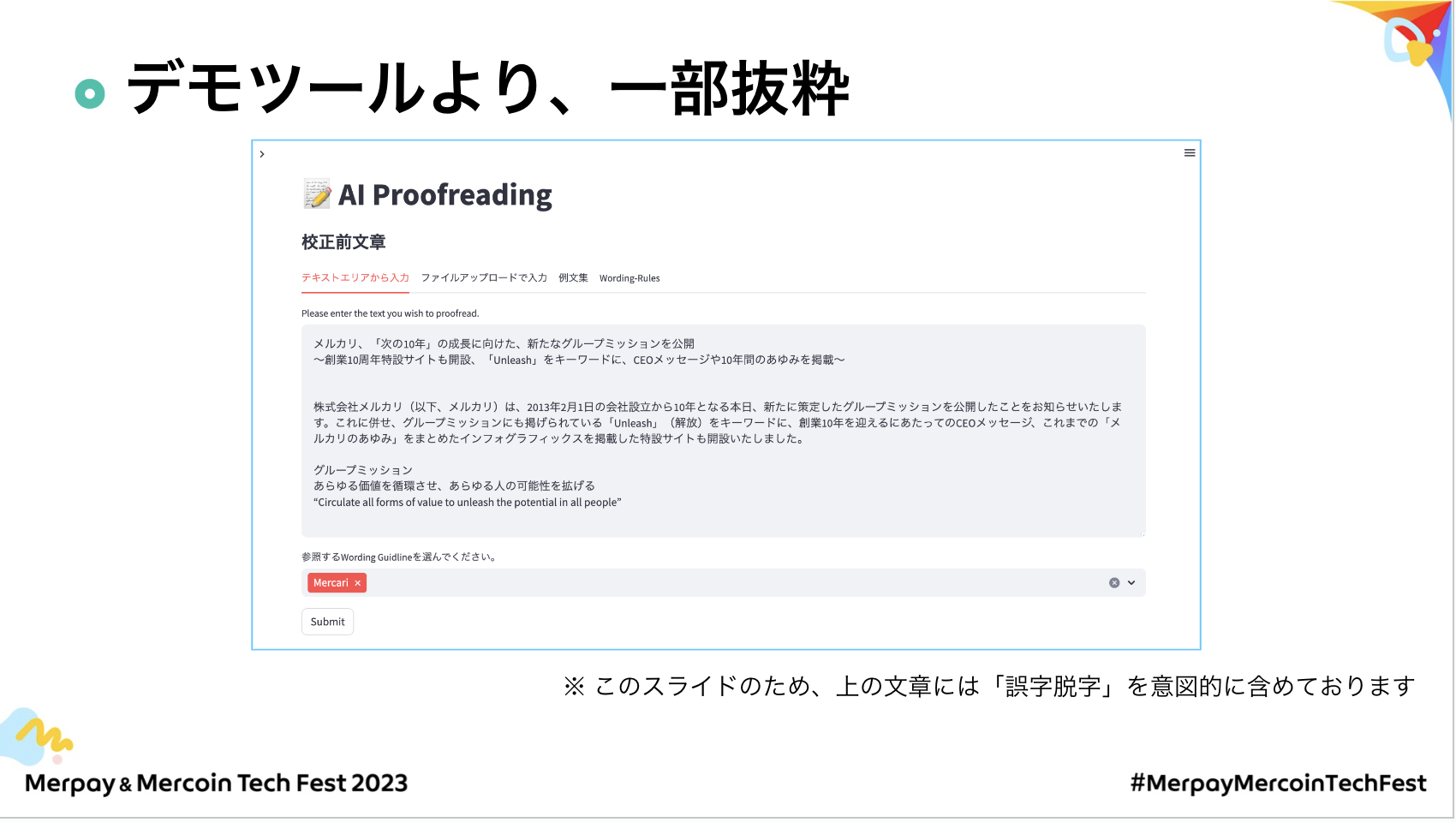
デモツールの実際に作った画面の一部を抜粋しながら説明していきます。
全体的にデモではあまり説明を入れずに使っていただけることを意識しています。最初に表示するテキストに例文が入ってるんですけれども、ここに校正したい文章を入力するとその下に結果が出てくるというシンプルな仕組みになっています。
特徴的なのは、会社ごとにチューニングされたワーディングルールがあるので、どの部分を活用したいかを利用者の人が選べるようなUIも作っています。Submitボタンを押すと処理が実行されます。

結果はこういった形になっていて、少し入り組んでいるので、少しずつご紹介したいと思います。
1個目がAnnotatedによる指摘です。これは、文章中でどこを指摘したかがわかりやすいように色付きで表示されるようになっています。また、色ごとに理由のカテゴリーが分かれています。
2個目に、指摘の解説です。指摘されている箇所がどういった理由で指摘されているか、どういったワーディングルールに基づいてるかを表示しています。
最後にSuggestion、これは全体の指摘を修正した文書が出力される場所となっています。利用者の方が、指摘がそのGPTによるモデルが合っているとは限らないので、利用者の方が、「絶対違う」というのがあったら、「採用しない」という選択肢も選べるようになっています。

次に裏側のロジックを簡単に紹介します。校正は簡単に三つのステップで成り立っています。
一つ目が、誤字・脱字・誤植や文法ミスのチェック。二つ目は、会社独自のワーディングルールに照らし合わせたチェック。最後に、内容が間違っている、あるいは最新の情報ではないなどのチェックです。

それらを実装するために、今回作成したフローは、こういった形になります。利用者の方が、インプットしてアウトプットするという流れに対して、それぞれ誤字脱字、ワーディングルール、公開情報とのチェックを行います。
全てLLMではなくて、自然従来の自然言語処理を使いつつ、OpenAIのChat completions APIのプロンプトで、柔軟に工夫しています、公開情報とのチェックについては外側からデータを入れ、どこが間違ってるかをチェックするという活用の仕方をして、フロー作りました。

最後にまとめに行きたいと思います。

今回のまとめとしては、LLMをGPT-3.5のモデルを活用して社内の文章校正ツールを作りました。文章の生成や修正理由の指摘はLLMが得意なところだったのでLLMに任せました。
逆にLLMでなくてもできるところは従来の技術や他の方法を使って棲み分けることで実現できました。
私自身MLエンジニアですがLLMという学習済みのモデルをどう使うかが、今までとは少し仕事の内容が違ったので、今後そういった取り組みを踏まえながら、どこでバリューを発揮できるかを考える機会になりました。今回とても面白いチャレンジングな取り組みができたんじゃないかと思います。

@nu2:ありがとうございました。先ほど、@toriさんからあったぐげん会議で私もスポンサードさせてもらったのが、障害報告書を自動生成するものでした。
そのような活用方法がデフォルトで考えうる使い方だなとは思います。FintechにおけるLLM応用の特殊性について、着々と実用化の準備が進んでいるとのことですが、Fintech事業ならではの応用について特殊なことってありますか。
@tori:一つ明確にあると感じるのは、金融商品は法律や自主規制など、いろいろな前提の上に乗っかっているもので、お客さまに伝えたいことも難しくなってしまうんですよね。
これに対して、ルールベースでいろいろコミュニケーション取ることはできますが、どうしても単調でわかりづらく、伝わらないこともあると思います。
こうした課題に対して、LLMは単調ではなく柔軟にしたり、固い表現を温かみのある表現にしたり、難しいものをわかりやすく変換して、よりプロダクトや金融商品とお客さまの距離を近くしてくれるアプローチに使える可能性があると思います。まさにLLMじゃないとできないポイントだと思います。
また、社外のお客さまとの接点だけでなく、社内にも全く同じ問題がありました。内部的なリスクチェックや省庁への報告などをエンジニアやリスク管理など、専門性をまたぐようなコミュニケーションに対して、同じ日本語を扱ってるんですけど、相互に理解したり、同一の文書にまとめたりするところが難しいです。
こうした社内のコミュニケーションやドキュメントをスムーズにして、結果として質の高い金融サービスをお届けするという点でも、可能性を感じます。
@nu2:障害報告書でもアウトプットに高い品質が求められると思うのですが、品質管理については今後どのように取り組んでいくかを聞かせてください。
@tori:正直言うと、悩みながらやっています。走りながら同時に道路を作っているようなイメージです。
Fintech関係なく、様々なドメインでそれぞれ共通的に気にするポイントがあるので、@mazeさんと連携しながら、社内の集合知としてガイドラインの形で作っています。ハルシネーションや、個人情報保護の観点、制度品質の担保などにフォーカスしています。
ただ、システム単体で見るというよりは、誰に対して向けているものなのか、お客さまとの間で取り決めするポリシーすらも変数として、総合的に必要な品質を考えるべきだと思います。

@nu2:もう少し応用性をちょっと深掘りして、ドメイン問わずお伺いしていきたいなと思います。私も今まで出てきたものにも触ったりしてるんですけれども、そんなに誰もが利用したいと思えるツールがChatGPT以外があんまり見当たらないなと感じています。
実際に現場で苦労しながら、取り組んでる点やどのような価値の創出や出し方が考えられていますか。
@mazu:ドメインを問わずで言うと、いくつか今入れてるところを抽象化して考えると、人が本来あまりやらなくて良いところや、機械化されることで人が解放されたり、クリエイティビティが発揮されるところに時間をより使えたりするところなど、何かにおまかせしたい仕事という部分がフィットするパターンが多いと思います。
クオリティ・精度を考えると、人手で時間をかければ90〜100%の精度でできるところも、スピードが重要で、60%の精度で良いところにLLMを使ってショートカットすべきところについては有効だと思います。
LLMを使わなくてもできるエリアでも使うことはあります。例えば、SEOのロジックにLLM使っていい感じのmetaタグ作ってみたり、分析のRAWデータを入れて、1人で分析するのではなく、GPTに分析してもらうことも、前処理的に入れるとかなり時間を短縮できるなという印象はあります。
@tori:ぐげん会議では、開発期間が1ヶ月もなかった中でとても良いプロトタイプが出せまして、これは一面でいうと成熟した技術をしっかり丁寧に使えば100点取れますが、LLMで60-80点のものを過去にないスピードで作れる長所が活きたということだと思います。
例えばテキストのポジティブネガティブ分析は、LLMでも準備なくとても良い精度のものが出せるので、これは典型だなと僕は思います。
@maze:おっしゃる通り、NLPを今ままでやってきた人にとって大変な作業が、すごい速さで実現できます。
@nu2:あとは、一般の方たちがどう使うかという問題もあると思います。我々はプロンプトエンジニアリングの観点で、コンテキストを突き詰めて、パフォーマンスを引き出す術を、ある程度もっています。一方で、一般のお客さま様・消費者は、何を聞いていいのかがわかりません。ハイコンテキストをローに落とすという変換が大事だと思います。

最後に、今後の方向性についても、お伺いできればと思います。
@maze:メルカリグループは非常にグループ間の敷居が低く、僕もメルペイに以前在籍をしていて、その後ソウゾウに行って今またメルカリに所属しています。引き続き各社グループ会社と連携しながら、それぞれが得た発見をなるべく共有していけるといいと思います。
プロダクト面については、メルカリグループにあるデータを活用して、お客さまの体験を便利にしていきたいです。解くべきIssue自体はこれまでと変わらないので、新しい手法で解決しに行くこと進めていけたらと思います。
社内の生産性の観点で言うと、生成AIを使える方をとにかく増やしたいです。なるべく社員が生成AIを使う機会を用意し、使いこなせるようにするサポートも引き続き進めていければと思います。生成AIを使いたいと思われてる方は、メルカリグループにジョインするとチャンスがあるんじゃないかと思います。
@tori:日々技術が進化していくので焦る気持ちもありますが、シンプルに長く使われる、かつLLMにしか解決できなさそうな問題に対してのプロダクトをリリースしていきたいです。

@nu2:メルカリ生成AI/LLMチームは、絶賛優秀な方を募集しています。スライドのQRコードを読み込んで、応募いただければと思います。

本日はご視聴ありがとうございました。




