Hi, I’m Yuanqin Lu, a machine learning engineer from the Image Search team in Mercari Japan. Mercari always tries to improve the experience for customers by helping them fastly put up items, easily find items, and conveniently buy items. In order to do so, product managers and engineers are working together on lots of Proof of Concepts (PoCs). Although not all of those PoCs will be released in Mercari recently, some of them are still inspired and possibly to be released in the future. Today I’d like to introduce one of the PoCs that will help customers fastly put up items to the market. Before that, let us show you what it is through the following video.
Background
In Mercari, a fashion item if put up with information of size, like shoulder width, body length, etc., is more likely to be sold. However, for a seller who has seldom put up the fashion items before, it takes a quite long time to measure all the sizes. For example, sleeve length, body width, body length, and shoulder width are usually demanded by a t-shirt. To measure the four sizes, in my case, it takes more than 3 minutes to do so. Also, even though a seller spends lots of time measuring, he is usually not confident in the results of the measurement. So, the motivation behind the PoC is to automatically, fastly, and accurately measure the sizes of the item by only taking a photo of it, as the PoC’s name automatic measurement says.
Difficulties of automatic measurement
Before we step into the details of automatic measurement, let me briefly explain the difficulties of the PoC.
Perspective effect
Perspective effect is that the size of an object could be different on a photo if the photo is taken at different distances or with lenses at different focal lengths. In general, if we take a photo with a lens at a fixed focal length, the farther the distance, the smaller the object on the photo. Correspondingly, you are not able to infer how large an object is from a photo as you are not aware of how far the object was while the photo was taken. We say that a single photo doesn’t include information of scale. Of course, there are several ways to obtain the scale, such as using stereo cameras to take several photos at the same time, utilizing continuous frames in a video with a single camera, and so on.
In our case, as we’d like to measure the size of a cloth item by only taking a photo, it would be pretty difficult as described above. So, how to obtain the scale from a photo is one of the crucial points in the PoC and we will elaborate it later.
Different measurements in terms of images and categories
Regarding the different images of cloth, the positions of measurements in each image can’t be the same, which means you can’t use a template for measurement. Furthermore, regarding the different categories of cloth, the type of size is different as well. How to flexibly measure sizes in terms of categories is also one of the most important issues that have to be handled.
Approach
As I mentioned above, there are at least two critical issues that have to be handled for the implementation of the PoC, i.e. how to obtain the scale from the photo and how to get the measurement from the photo.
Obtain the scale
If you are a user of iPhone, I believe that many of you have ever tried the built-in app Measure which utilizes ARKit to measure the length between points that are manually specified by users.
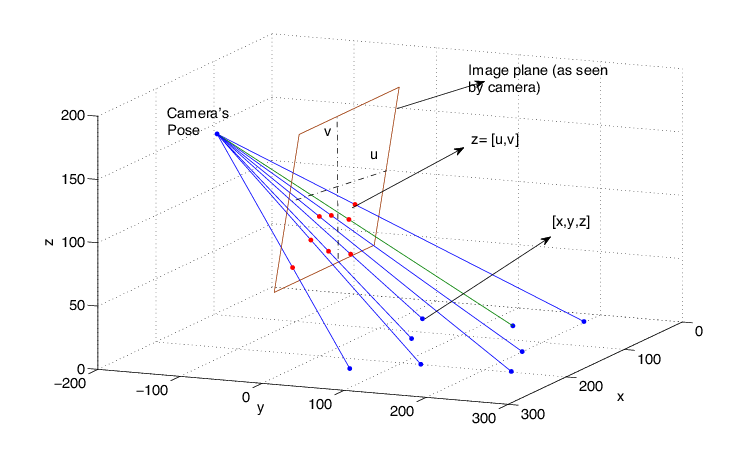
The principle behind the app is a kind of algorithm that utilizes the continuous frames to estimate the camera’s pose, by which we are able to map the points in an image captured by the camera to the world, as Figure 1 shows. In other words, if a camera’s pose could be estimated, the issue of scale in an image is solved at the same time. As there are many mature algorithms to estimate a camera’s pose, we are not going to dig deep with it. Thanks to ARKit in iOS and ARCore in Android, we are able to easily obtain the camera’s pose by utilizing the API of them, and we are able to tell how far in the real world between two arbitrary points in the image.

Get the measurement
In order to get the measurement, we borrow the idea from a typical computer vision task: human keypoint detection, where the joints of human beings are detected in an image. As the sizes of cloth are measured from point to point, like shoulder width is measured from the left shoulder point to the right shoulder point, we designed a single cloth keypoint detection model similar to [2] to predict these predefined keypoints for measurement if an image with only a single cloth is given, such as 10 keypoints for a T-Shirt as Figure 2 shows. In order to train the model, we prepared more than 10K images of items that have been put up in Mercari. To make the model more robust, we prepared various images regarding different photo qualities, different lighting conditions, and types of cloths. Also, we must appreciate the annotation team in Mercari to help us annotate all the data in a very short time. Without their efforts, this PoC can’t be completed at all.

In order to predict keypoints for different categories, the model is designed to be general and to be easy to extend. On the other hand, different categories require different types of keypoint for measurement, so combining the keypoint detection model with a classification model that decides which keypoints to be used is one of the solutions.
Conclusion
At last, with a combination of AR and the keypoint detection model, we are able to automatically measure the sizes of cloth by simply taking a photo of it. By combining AR with other machine learning techniques, there will be many interesting features that benefit users of Mercari. This PoC is just one of the trials, and we’re looking forward to creating more interesting and useful features to help our customers get a better experience in Mercari.
Reference
- Camera pose estimation using particle filters – Scientific Figure on ResearchGate. Available from: https://www.researchgate.net/figure/Camera-pose-position-and-orientation-estimation-from-observing-eight-LED-markers_fig1_229033775 [accessed 10 Jun, 2020]
- Xiao, Bin, Haiping Wu, and Yichen Wei. “Simple baselines for human pose estimation and tracking.” Proceedings of the European conference on computer vision (ECCV). 2018.



