この記事はMERPAY TECH OPENNESS MONTHの15日目の記事です。
こんにちは。メルペイのPayment PlatformチームでPaymentServiceの開発を担当するエンジニアの @foghost です。
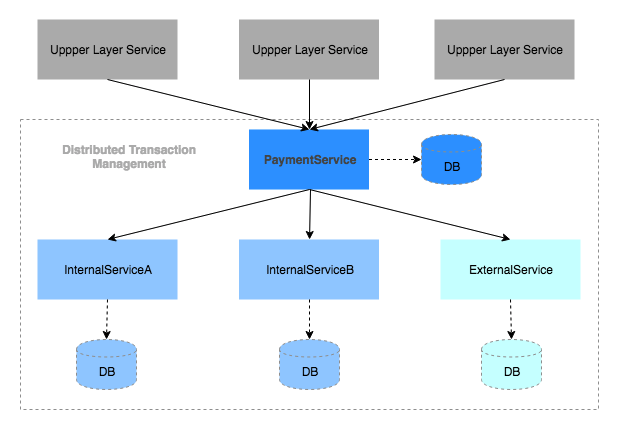
メルペイではマイクロサービスのアーキテクチャで決済システムを開発しています。その中でPaymentServiceは決済トランザクション管理の基盤サービスとして、下位層のサービス(外部サービスも含め)が提供する各種決済手段を利用して、上位層のサービス(メルカリ、NFC,コード払いなど)に必要な決済フローを共通APIとして提供しています。PaymentServiceが提供する決済処理に複数のサービスを跨いでお金の動きを正確に管理する必要があるので、作り始めた頃から決済トランザクション管理を最も重要な課題として、サービスを跨いでもデータの整合性が取れる仕組みを作ってきました。

本記事では、マイクロサービスにおける決済トランザクション管理の難しさを簡単な例で説明して、その後PaymentServiceで実践してきたいくつかの手法を簡単に紹介したいと思います。
分散システムにおけるデータ整合性担保の難しさ
マイクロサービスやSOAなどの分散システムにおけるデータ整合性担保の難しさを説明するには、まず1つの例をみてみましょう。
あるお客様が加盟店に対して、2つの決済手段で1000円(内部サービスで管理するポイント600円+外部サービス経由でクレジットカードで400円)を支払う場合、決済処理としてざっくり以下の処理を必要とします。
- 決済処理のトランザクションデータ作成
- ポイント600円を消費する
- クレジットカード400円を消費する
- 加盟店の売上金に1000円を付与する
- 決済の結果通知を送信する

上はシステム上何も工夫しない場合のシーケンス図です。すべてが正常に処理された場合、上記のように⑦番まで実行されて成功が返せます。しかし、現実の世界ではネットワークの障害や、依存先のサービスの障害が絶対発生するので、途中で処理が落ちた場合、どうやって複数のサービスを跨いで決済トランザクションのデータの整合性を担保するのかが大きな課題になります。
全部は網羅しませんが、途中で処理が落ちた場合、以下のような状態が発生する可能性があるかと思います。
- ①番のところでタイムアウトが発生した
- InternalServiceAの中で、600円のポイントが消費された可能性がある
- ②番(もしくは②番以降)のところで、Upper Layer Service側で設定されたタイムアウトの時間を超えて、リクエストが切られた
- PaymentService経由してInternalServiceAの中で、600円のポイントが消費されたかどうかわからない
- ③番のところでタイムアウトが発生した
- InternalServiceAの中で、600円のポイントが消費された
- ExternalServiceの中で、400円の与信枠が消費されたかどうかわからない
- ③番のところで、ExternalServiceから残高不足などのアプリケーションエラーが発生した
- InternalServiceAの中で、600円のポイントが消費された
- ④番のところでタイムアウトが発生した
- InternalServiceAの中で、600円のポイントが消費された
- ExternalServiceの中で、400円の与信枠が消費された
- InternalServiceBの中で、加盟店に1000円付与されたかどうかわからない
- ⑤番のところでタイムアウトが発生した
- InternalServiceAの中で、600円のポイントが消費された
- ExternalServiceの中で、400円の与信枠が消費された
- InternalServiceBの中で、加盟店に1000円付与された
- MessageQueueにイベント送信されたかどうかわからない
- ⑥番のところで、ローカルDBのコミットが失敗した
- InternalServiceAの中で、600円のポイントが消費された
- ExternalServiceの中で、400円の与信枠が消費された
- InternalServiceBの中で、加盟店に1000円付与された
- MessageQueueにイベント送信された
- DBコミットに失敗すると、トランザクションデータなくなり、↑の処理で利用されたトランザクションIDを失ってしまう
これらのケースそれぞれ発生したときに「どうやってハンドリングすればお客さまのお金を正確に管理できるのか」を一度考えてみれば、分散システムにおけるデータ整合性担保の難しさを少し分かっていただけるかと思います。
既知の手法
分散トランザクションモデルとして、XAと言ったプロトコルが昔から提唱されており、2PC(2 phase commit)などの手法がよく知られています。MySQLでも2PCによるXAトランザクション機能を提供しています。ただし、2PCの場合、実行中すべての参加者がブロックされるなどの問題があり、性能と可用性上の懸念があります。
そして、XAのようなグローバルトランザクションとしてACID特性を担保させる手法に対して、Eric Brewer氏が「CAP定理」と一緒に「BASE」という可用性や性能を重視した分散システムの特性を2000年頃に提案しました。


「CAP定理」は、分散システムにおいて以下の3つの要素を2つしか同時に満たすことができないことを示します。
- C: Consistency (一貫性)
- A: Availability (可用性)
- P: Tolerance to network Partitions (ネットワーク分断への耐性)
「BASE」というのが、基本的には常に利用可能で、一時的に一貫性のない状態を許容して、即時ではなく結果整合性を取る特性になります。つまりCAPの中でAPを重視して、C(Consistency)のところを少し緩めたシステムが持つ特性です。
実際のサービス開発におけるBASEの応用例は、2008年eBayのPritchett氏が書いた 「Base: An Acid Alternative」をみていただけるとイメージがわくと思います。
また中国で人気のモバイル決済サービスアリペイ(執筆時現在(2019年6月)10億ユーザーに利用されている)が2008年頃発表したキーノートにも、大規模SOAシステムにおけるBASEの応用事例が書かれています。TCC(Try/Confirm/Cancel)や補償トランザクションなどの手法を利用してBASE特性に準じた決済システムを当時から作り上げていたようです。

TCCというのは、メインサービスが依存先サービスのある処理(例えば残高を減らす)を行うときに、依存サービス側で該当する処理をTry/Confirm/Cancelという3つの処理をAPIとして提供して、メインサービスはコーディネーターの役割を果たしてそれらの操作を使って全体のデータ整合性(結果整合性)を担保する手法です。
- Try: 依存する先のサービス側で処理に必要なリソースや状態などの仮押さえを行う、Tryで押さえられたたら、Confirm処理が必ず成功する、もしくはCancel処理経由でロールバックもできるのがポイントです。
- Try処理のフェーズで、依存先のTry処理が一つでも失敗(タイムアウトなど)したら、成功したサービスのCancel処理をそれぞれ成功まで実行してロールバック処理を行う
- Try処理がすべて成功したら、依存先のサービスのConfirm処理を成功まで実行する。
PaymentServiceで実践してきた手法
既に述べたように、PaymentServiceではお客様のお金を正確に管理するため、初期からトランザクション管理の課題と向き合って、複数のサービスを跨いでも全体的な決済トランザクションの整合性を担保できる仕組みを模索しながら作ってきました。
マイクロサービスごとに利用されるストレージは異なる可能性があり、クレジットカード等の外部サービスとの整合性を取る必要もあるため、PaymentServiceでは最初からDBが提供するXA(2PC)などの分散トランザクション管理機能に依存しない方向で、アプリケーションのレイヤーでデータ整合性の担保する戦略を採用してきました。
結果的にeBayやアリペイでも実践してきたような可用性と性能を重視した結果整合性が取れるシステムになっています。これからは実際にやってきたいくつかの手法について紹介します。
決済トランザクション処理の細分化
決済処理中にエラーが発生した場合、発生するエラーの種類と処理がどこまで進めたのかによって、取るべきハンドリングが分かれます。
- リトライして直せる問題であれば、必要なリトライ処理 を行う
- 即時でリトライできなかった場合、バッチであとでリトライするパターンもある
- リトライで直せない問題であれば、依存先のサービス含めて、必要なロールバック処理 を実行してから、処理を終了する
この中で、 必要なリトライ処理 と 必要なロールバック処理 を判断するには処理がどこまで進めたかをまず知る必要があります。
はじめにあげた例では、1つの大きいトランザクション処理として実行されるので、途中で処理が落ちた場合、どこで落ちたのかわからなくなるので、あとで復旧が困難になります。

PaymentServiceでは1つの決済トランザクション処理を複数のフェーズに細分化して実行するようにしています。
- 決済処理を受付時に内部トランザクションデータとIDを必ず一つのフェーズとして確定してから処理する
- フェーズの進行状態を必ず記録する
- フェーズの粒度はリトライとロールバック処理のやりやすさによって決める
- 依存先のサービスに対して1つ操作した場合、基本1つのフェーズとして分けて、操作時のログも細かく残すようにしている
処理の細分化によって、処理時もしくは途中で落ちたとしても、現在記録されているフェーズを参照して、取るべきリトライもしくはロールバック処理の範囲を絞りながら、より簡単に復旧できます。
ステートマシンで実装されるコーディネーター

ある決済処理の状態遷移がこのようになっているとします。
- Created: 決済受付
- Paid: 支払い成功した
- Failed: 支払い失敗した
- Refunded: 返金がある場合、返金された
上で説明した決済処理の細分化を行ったあと、各処理フェーズもある種の中間状態になります。PaymentServiceでは、各処理フェーズのステート定義、必要な処理、状態遷移を含めて決済処理ごとに定義して、ステートマシンの仕組みを使って決済のトランザクション処理のコーディネーターを実装しています。

ステートマシンで実装するメリットは以下のところがあります。
- フレームワーク化されるため、最初から決済処理の細分化を考えながら実装される
- 各フェーズでエラー発生したときに、それぞれのフェーズが必要に応じて、リトライもしくはロールバック処理を実行することができる
- リトライ処理の範囲が絞りやすくなり、必要な分だけ実行すればよい
- ロールバック時のトランザクションも、それぞれのフェーズが必要なRollback処理を状態遷移に追加すれば実装できる
- 細分化された各フェーズの実行状態の管理はステートマシンでの共通の仕組みで管理されるため、特に意識しなくても自然で統一的に管理される
- 管理がある程度統一されるため、自動復旧の仕組みも共通で作りやすくなる
- フェーズの共通化もやりやすくなる
デメリットもいくつかあります。
- プログラムが上から順番に書かれていないので、プログラミングの難易度が少し高くなる。
- 新メンバーが入ったとき、慣れるまでキャッチアップの時間がかかる。
- 状態遷移でつながる処理がトリガーによってルートが変わることがあるので、頭の中でも予測可能(Predictable)なプログラムを書くのに工夫が必要
- テストを書くことがとても大事になる
- デバッグの難易度が上がる、適切にログを残すのが大事
- フェーズの定義が細かすぎると、パフォーマンスに影響を与えてしまう可能性もある
冪等性
決済処理中リトライ処理が発生した場合、何も考慮しない場合、依存先サービスに投げる操作が多重に実行されたらお客様の残高が何度も引かれてしまう問題が発生します。
このような操作、多重に実行しても結果(残高が一度のみ引かれる)が変わることがない特性のことを、冪等性と呼びます。
決済処理の冪等性を担保するため、主に2つの手段が考えられます。
- 操作結果を参照する手段を用意して、呼び出し側で再実行する前に必ず結果を確認してから行う
- 呼び出される側の操作自体を冪等性が担保される前提で作って、何度も実行しても同じ結果になる
1の場合、再実行するときに参照するため1リクエストを投げる必要あるため、場合によってパフォーマンスに影響が出る可能性があります。そして実装上参照して結果確認する処理がもし漏れたら、事故の元になるので、メルペイでは、基本的に2の方針で各サービスが冪等性のあるAPIを提供することが強く要求されています。
- APIの提供側は、リクエストのパラメータとしてIdempotency Keyを必ず受け取って冪等性担保できるように実装する
- APIの利用側は、多重処理されないようにユニークなIdempotency Keyを生成してAPIを叩く

PaymentServiceの場合、決済処理を受け付けたときに内部のトランザクションIDを一度確定してからお客様の残高を減らす操作しています。そして、残高を減らすときに、依存先のサービスが提供する残高操作API(冪等性が担保されている)に確定された内部のトランザクションIDをIdempotency Keyとして渡せば、何度も実行しても残高が一度だけ引かれることが保証されます。
補償トランザクション
決済処理の途中で、どうしても前に進められない場合、今まで実行してきた操作を一度きちんとロールバックしてから失敗を返す必要があります。そのための処理が補償トランザクションと呼ばれています。
例えばはじめに書いた例だと、内部サービス(InternalServiceA)が管理されるポイントの消費が確定された後、外部サービス(ExternalService)クレジットカードでの決済が失敗したら、そのままで処理終了して失敗を返すと、お客様にとって決済が失敗したのに、ポイントが消費された状態になってしまって不整合が発生します。

PaymentServiceでは、正常のトランザクション処理と共に、ロールバックするための補償トランザクション処理もステートマシンで管理して、必要に応じて実行して決済処理の整合性を担保しています。
まだ、補償処理としてよりきれいにロールバックしたいとき、上で紹介したTCCのやり方と同じく、1つの操作を仮押さえと実行の2つの分割する手法も採用しています。
例えば残高消費の処理には金額の消費と履歴の記録処理があった場合、一つの操作にまとめると、ロールバック処理が実行された後に金額は正しく返せますが、履歴が汚れる問題が発生します。
それに対して、仮押さえと実行の2つに分けたら
- 仮押さえの段階では、残高を仮売上状態として押さえるだけ
- 実行したら実売上と履歴の記録処理が走る
仮押さえの後にロールバック処理を走ったら、履歴が汚れるなどの副作用も抑えながらよりきれいな補償処理が実現できます。
リコンサイル
ここまではアプリケーションレイヤーで決済処理の整合性を担保する手法について説明してきましたが、実際にシステムに作り込んで本番にリリースした後、本当に決済処理のデータ整合性がちゃんと取れてるかどうかについて、何らかの方法で確認もしくはモニタリングする必要があります。メルペイでは各サービス間のトランザクションデータのリコンサイル(データ突合)処理を行っています。万が一不整合を検知したら、早急の復旧対応及び今後向けの根本対策が求められています。
PaymentServiceでは、内部トランザクション処理の不整合検知と自動復旧を行った上で、バッチ処理で会計データや残高などの管理システムとのリコンサイルも行っています。また、PaymentServiceに依存する上位レイヤーのサービスも同じくPaymentServiceとのリコンサイルを行い、メルペイ全体の決済システムの整合性を担保するようにしています。
リコンサイルの手法は主に以下の2つが使われています。
- バッチでローカルで確定した冪等キーやトランザクションIDを使って、依存先のサービス側が提供する参照APIで同期的にデータの突合を行う
- 依存するサービス側が非同期で送信する結果イベントを利用して、ローカルのトランザクションデータと非同期的に突合を行う
Fault Injection Testing
決済処理を実装するとき、正常処理よりも異常処理のほうが数倍難しいです。
理想上、発生しうるすべての異常ケースの一覧があれば、ここまで紹介した手法をちゃんと取り込めばリリース前からすべての異常ハンドリングができて、データ整合性が自動的に担保できるはずです。
ただし、現実の世界ではそんな異常ケースの一覧がどこにも明確化されていません。ビジネスロジック上の内部要因で発生する異常ケースの洗い出しはまだ簡単ですが、ネットワーク問題や依存先サービスの障害などの外部要因による異常ケースの洗い出しや予測は簡単ではありません。
PaymentServiceでは外部要因で発生する異常ケースを実行中にランダムに発生させるために、Fault Injection Testingの仕組みが作られています。例えば、ネットワークによるタイムアウト、DBから異常エラーの発生、依存する外部サービスへの接続不安定などを共通のインジェクションケースとして用意して、全ての決済処理はUnit Test, e2e Test以外、Fault Injection Testも必須にすることで、実装された異常ケースのハンドリングの網羅度が検証できます。
そして、このような仕組みによって、新しく開発した決済APIでも、リリースしなくても本来予測困難な異常ケースを事前に発生させることで、データ不整合や冪等性の問題を事前に解消でき、より高い品質でリリースできます。
おわりに
以上、マイクロサービスアーキテクチャを採用すると絶対一度は悩まされるトランザクション管理の話でした。ここに紹介された以外の手法も色々あるかと思います。そしてメルペイはまだスタートしたばかりなので、これからもプロダクトの進化とともに、常によい方法を模索しながら決済トランザクション管理の仕組みを進化させて行きたいと思います。