Hello! My name is Daiki (Twitter: @dkumazaw), and I am a software engineer intern in the AI Engineering team. Today, I would like to share how we reduced our engineering workload by utilizing multimodal neural architecture search (NAS) for prohibited item detection tasks.
The essentials
- With more than 10 million monthly active users and growing, our marketplace faces increasing demand to identify and preemptively remove listings that violate our platform’s terms of service
- We are tasked with developing ML-based violation detection systems that leverage multiple modalities of available data to attain high precision
- In building such multimodal ML systems, there were two challenges: (1) less is known about the best practices for multimodal modeling than single modality settings, and (2) the ever-changing nature of regulations necessitates a scalable approach to build new models
- We developed a DARTS-like NAS system to automate designing a multimodal neural network architecture
- This reduced time-to-production of a new model from a few months to a few weeks

Task at hand
With more than 10 million monthly active users utilizing the Mercari marketplace, a large number of items are posted on our platform for sale every day. A fraction of these items, however, violate our platform’s terms of service and should not be listed on the market. Although these items should be immediately removed, with the finite customer support capacity, it is impractical for us humans to go through all listings and detect these violations.
To tackle this problem, our team has been developing ML-based methods to detect prohibited items. Since falsely removing compliant items will lead to a poor user experience, our models need to attain the highest possible precision. Thus, we hope to leverage the multiple modalities of data available to us, including item images, text descriptions, prices, and so forth. However, unlike single modality settings such as image classification where off-the-shelf networks like ResNet achieve relatively high performance, less is known about the best practices for multimodal modeling. This leads to more challenges in the modeling process.
Moreover, violation categories change over time owing to changes in Mercari’s terms of service as well as external regulations, which necessitates a scalable method to quickly build new models whenever violation categories are altered or added. This led us to develop and utilize an AutoML-like system that can quickly build a performant multimodal architecture.
Our approach
Our proposed system utilizes neural architecture search (NAS). As the growing body of literature has shown in the past few years, NAS-based methods are known to discover neural network architectures that often perform better than models designed by humans.
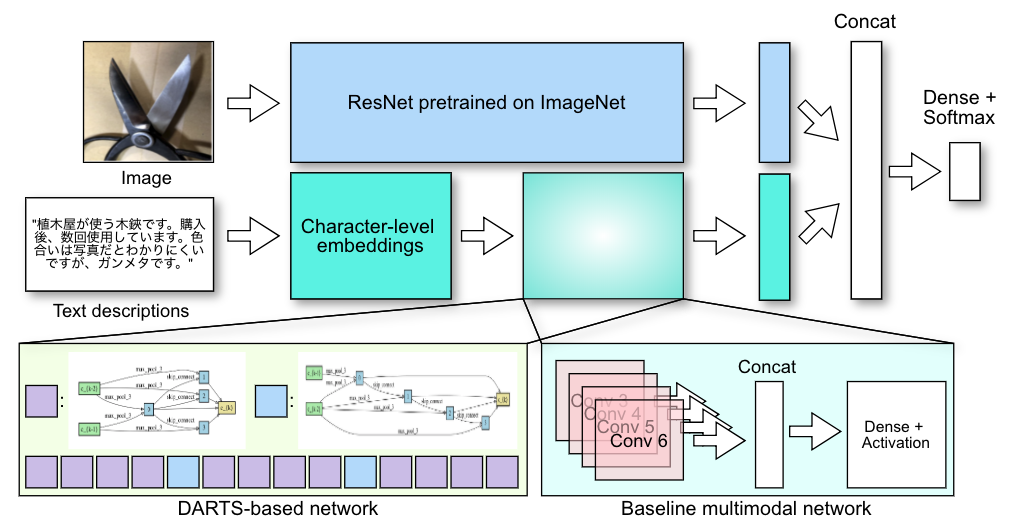
The proposed system and the baseline method against which we validate our proposed system are as shown in Figure 1. The baseline network replicates a violation detection model already deployed for one violation category. In the proposed system, we adopted a DARTS-like differentiable architecture search as our architecture optimization strategy because of its relatively low search cost and simple implementation.
To leverage multimodal inputs, our proposed method joins features from the image and text branches. The text branch consists of a stack of cells, whose internal structures are searched by gradient descent similar to DARTS. A cell is a directed acyclic graph of operations and produces some intermediate features as its output. Like the original DARTS paper, we consider two types of cells: a normal cell that preserves the shape of the input, and a reduction cell that downscales the input shape by half. The normal cell will be stacked multiple times to build the text branch, interleaved with the reduction cell in every one third of the total length of the branch to form the full network. The allowed operations within each cell are one dimensional in order to accommodate textual inputs.
The candidate operations are convolutions with kernel sizes 3 and 5, dilated convolutions with kernel sizes 3 and 5, max pooling with kernel size 3, average pooling with kernel size 3, skip connection, and zero operation.*1 The image branch of the network uses a CNN pre-trained using ImageNet in order to benefit from transfer learning.
Training procedures for the proposed method and the baseline network proceed as follows. Following what has been done in DARTS, training the proposed model will consist of a search phase and an evaluation phase. The search phase trains the architecture parameters and weight parameters alternately in order to determine the optimal architecture skeleton. Then, the evaluation phase trains the discovered architecture on the target task from scratch to obtain the final classifier. The baseline, on the other hand, does not require a search phase since the architecture is predetermined, and the evaluation phase corresponds to training the model on the target task as usual.
Experiments
For our experiments, we selected six violation categories to compare the two methods’ performances. For each of these categories, we obtained a multimodal dataset containing both prohibited items (labeled positive) and normal items (labeled negative). Since the actual ratio of the number of normal items to that of prohibited items is highly skewed, the negative pool is downsampled to 300,000 items in order to make the imbalance less extreme.
For the search phase, it is common practice to use a smaller proxy dataset because of DARTS’s high GPU memory requirements. For this experiment, we used a subset of the obtained six datasets to find an optimal architecture skeleton shared across the six categories rather than creating one architecture for each category. More precisely, we sampled a balanced dataset of 60,000 items from the six datasets, where each violation category was drawn by stratified sampling.
The search phase of the proposed method took 2 days on a single NVIDIA Tesla P100 GPU, and training the discovered architecture on the target task took 1 day for each category. Training the baseline network took 1 day for each category with the same GPU specification.
Results
In Figure 2, we present the discovered cell structures for the normal and reduction cells after the search phase. Despite the fact that the allowed operations include 1D convolutions and dilated convolutions with various kernel sizes, the selected operations are max pooling layers with kernel size 3 and skip connections, suggesting that fewer parameters may be necessary for our tasks.


To compare the performance of the two methods, we focus on average precisions as well as recall and precision scores at various thresholds as key metrics. On Table 1, we report precision and recall scores on the unseen offline test set, whose positive-to-negative ratio is about 1:3, with the threshold value set to 0.9 for the positive class. We observe high precision scores for both the baseline and proposed methods, although the DARTS-based network slightly outperforms the baseline in all categories. The difference is more obvious in recall scores, where the proposed method’s recall is higher than the baseline by more than 0.15 in a few categories.

Another important implication is that despite the improvements made by the proposed method, Categories A and B are more difficult to model compared to the other categories. We note that these categories are known to us to have higher intra-class variability, and we may benefit from further feature engineering in addition to applying this AutoML-like system.
Impact
The multimodal NAS system we developed has been integrated into our data ETL platform so that we can quickly build and deploy a violation detection model for a novel violation category. It used to take up to a couple of months to develop and deploy a new model—from collecting data, conducting feature engineering, modeling an architecture, validating performance and making the model production-ready. Now, within a few weeks, we can build and deploy a performant model generated by NAS. This allows us to spend more time on harder violation categories or on other tasks that require more attention from us ML engineers.
Thank you for reading, and we hope to share more about how we utilize cutting-edge ML techniques to improve our users’ experience on our marketplace. I also plan to release the Japanese translation of this blog post in the near future, so please stay posted!
*1:We note that we took a one-dimensional CNN approach to the text feature extraction because our listings’ text descriptions tend to be nonsensical as natural language. For example, they may simply be a collection of words that describe the item. This suggests that non-sequential operations like convolutions could suffice for our purposes.



