Hello, I am Kumar Abhinav from the Machine Learning Team at Mercari Inc. Japan.
We at Mercari are constantly working with cutting edge technology to enhance the customer experience and create an efficient global marketplace where anyone can buy and sell. This article is about the client-side machine learning using TensorFlow Lite and also describes the related project currently being developed at Mercari.
My presentation on client-side machine learning can be found here.
From building the first checkers playing machine (1952)[1] to beating humans in Go board game (2016)[2], machine learning has seen a lot of developments over time. Recent research aims to make machine learning more approachable and usable to the users. With the development of high computational power embedded devices, scalable and fast machine learning implementations have become feasible. This has enabled client-side (on-device) machine learning inference, replacing the need for server-based inference.
In this article at first, we will discuss client-side computing in the machine learning domain, it’s benefits and challenges as compared to server-side implementation. Next, we introduce TensorFlow Lite, a tool for client-side machine learning and then discuss on it’s working architecture, operators and finally the implementation limitations. We then discuss a practical implementation of client-side machine learning by giving an overview and results of the Similar Image Search project carried out in Mercari. We finally conclude the article by giving a glance at its future.
- Client-Side Computing
- Introduction to TensorFlow Lite
- Similar Image Search at Mercari
- Future of Client-Side Computing
- References
Client-Side Computing
There are two major parts of the machine learning modeling process, training and inference. The Training process is generally bulky, where you teach your model on how to interpret data. The problem for machine learning on mobile is that training is computationally heavy. Most machine learning models today train on specialized hardware like desktop GPUs, thus it usually happens in the cloud on powerful servers. Inference, the second part of the modeling process, typically requires significantly less compute power than training, making it a more realistic task for less-powerful edge devices.
Client-side computing (or edge computing) is where data is processed locally rather than sending it to a cloud server. With respect to machine learning, client-side computing means inference is done on the device.
Client-side computing provides certain benefits over the server-side implementation, such as:
-
Real-Time Inference:
Although inference computing on edge devices is hardware dependent, it’s certainly faster than waiting to retrieve API’s result over the network. Analysis of live video and model inference in real-time can be achieved. -
Offline Capability:
Client-side computing enables model inference without the need for an internet connection. End to end inference can be achieved offline if the models and labels are already present at the edge device. -
Data Privacy:
Secure inference without any image or video sharing can be achieved as no data is being sent across the internet or stored in the cloud database. -
Reduction in Cost:
There is a reduction in the server cost since you no longer need ML servers. In addition to this, there is a reduction in the data transfer network cost as images or videos aren’t being sent to the server.
However, with significant benefits come certain challenges. Since machine learning models are deployed on edge devices, there is a restriction on the model’s size due to hardware and processing power. Accuracy tradeoff becomes noticeable in weak and small networks due to restrictions on the model size. Client-side inference time is heavily dependant on edge device’s hardware and working condition, thus measurable latency can be observed in low-end devices with weak processors. For a technology company, updating the machine learning model frequently on the client side is challenging as compared to its server-side implementation. These updates can only be rolled out with version updates which can’t be done often.
Over the past few years, the open source community has worked on solutions for client-side machine learning inference. Some of the popular tools for client-side machine learning are TensorFlow Lite (Google), Core ML (Apple), Caffe2Go (Facebook) and ML Kit (Google). TensorFlow Lite is used in this article as a tool to explain client-side machine learning.
Introduction to TensorFlow Lite
Overview
TensorFlow Lite (or TFLite) is the lightweight client-side machine learning inference tool for mobile and embedded devices from the TensorFlow community. The predecessor to TFLite is TensorFlow Mobile, being the first mobile machine learning tool from TensorFlow. However, TFLite, introduced in May 2017, is seen as an evolution of TFMobile with smaller binary size, fewer dependencies, and better performance. TensorFlow Lite is currently supported for Android, iOS and Raspberry Pi.
TensorFlow Lite use FlatBuffers[3]-based model file format (called .tflite), replacing the Protocol Buffers[4] used by TensorFlow. FlatBuffers are memory efficient and lightweight with a tiny code footprint and are generally used in the gaming industry. They are cross-platform and are flexible with forward and backward compatibility. The primary difference from Protocol Buffers is that FlatBuffers don’t need a parsing or unpacking step to a secondary representation before accessing the data. Additionally, Protocol Buffers do not support optional text import/export nor schema language features like unions.
TensorFlow Lite supports a set of core operators tuned for mobile platforms, both quantized and float. It incorporates pre-fused activations and biases to enhance performance and quantization accuracy. The TFLite kernels are smaller than 300KB when all supported operators are loaded. It also has Java and C++ API support along with model support for InceptionV3[5], MobileNets[6], and other common model architectures.
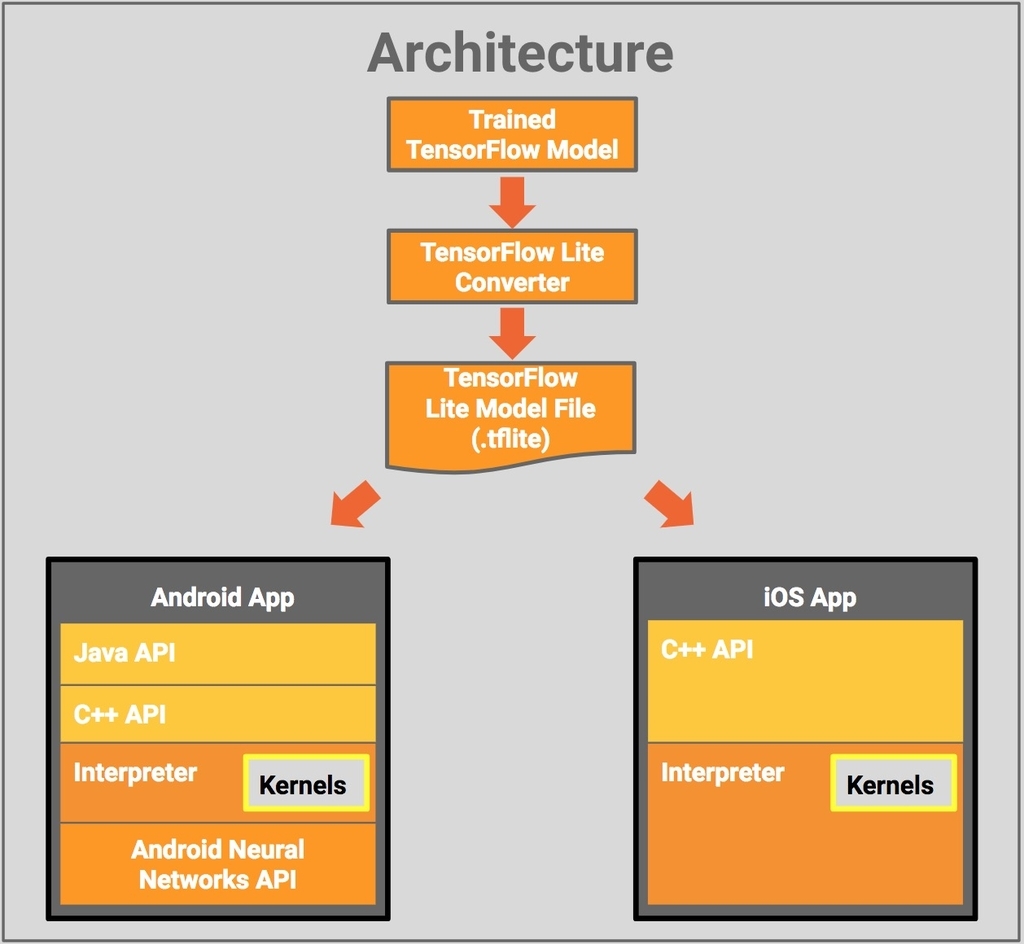
Architecture
The architectural design of TensorFlow Lite is described below:

At first, the trained TensorFlow model is converted to the TensorFlow Lite file format (.tflite). The converted model file can then be deployed in the desired mobile application. Java API is provided for Android App which acts as a convenience wrapper around C++ API. C++ API is available for both Android and iOS, which is used for loading the TFLite model file and invoking the interpreter. The Interpreter executes the .tflite model using a set of kernels. The Interpreter uses Android Neural Networks API[7] for hardware acceleration on select Android devices, else CPU execution is carried out for normal devices.
Converter and Interpreter
TensorFlow Lite has two key features namely Converter and Interpreter. The TensorFlow Lite Converter uses the TensorFlow graph file or saved model to generate a TensorFlow Lite FlatBuffer based file which is then used by the TensorFlow Lite Interpreter for inference. The generated .tflite file after the conversion process is used at the client-side for an on-device inference. The entire process is shown in the diagram below:

The TensorFlow Lite Converter uses the following file formats as input:
- SavedModels
- Frozen Graphs (models generated by freeze_graph.py )
- Keras HDF5 Model (tf.keras)
tf.SessionModel
Any of the first three input file formats can be converted to FlatBuffer format (.tflite) by TensorFlow Lite Converter either from Python API or from Command Line. However conversion of a model from tf.Session can only be done through Python API.
The inference from the FlatBuffer file (.tflite) is carried through TensorFlow Lite Interpreter. The following code demonstrates a sample inference being run on random input data:
Inference can also be achieved within a graph session without actually saving the FlatBuffer based file.
Discussion
In January 2019, GPU backend support for TensorFlow Lite delegate APIs on Android and iOS was released. Here are some of the notable benefits of GPU Acceleration:
GPUs are designed to have high throughput for massively parallelizable workloads. […]
Unlike CPUs, GPUs compute with 16-bit or 32-bit floating point numbers and do not require quantization for optimal performance.
[…] GPUs carry out the computations in a very efficient and optimized manner so that they consume less power and generate less heat than when the same task is run on CPUs.
See TensorFlow Lite GPU delegate Documentation.
However, some operations that are trivial on the CPU may have a high cost on GPU inference (e.g. Reshape ops: BATCH_TO_SPACE, SPACE_TO_BATCH, SPACE_TO_DEPTH). Also on GPU, tensor data is sliced into 4-channels. Thus, a computation on a tensor of shape [B,H,W,5] will perform about the same as on a tensor of shape [B,H,W,8] but significantly worse than [B,H,W,4].
TensorFlow Lite is currently going through a fast pace of improvements. However, below are a few limitations in current implementation which may be resolved in future releases:
- TensorFlow Lite doesn’t accept variable input image size, only the first value (batch size) of input tensor can be variable, e.g.:
T = [?, 224, 224, 3]. - Current TensorFlow Lite implementation doesn’t support
uint8during model training thus it is advised to usefloat32. - There is little or no support available for
tf.float16andstrings. - Not all operators of TensorFlow are supported in TensorFlow Lite.
- TensorFlow Lite supports only TensorFlow’s NHWC data format.
Similar Image Search at Mercari
We at Mercari are working on Client-Side Similar Image Search project powered with TensorFlow Lite for Android devices. We are using MobileNet V2[8] based feature extraction model for our purpose. The input image tensor is of the form [224, 224, 3] and the output tensor is the Global Average Pooling Layer of vector length 1792, generated using the hyperparameter width multiplier (1.4). We have quantized the model using TFLite from 17.6 MB (Original TF Model) to 4.4 MB (Quantized TFLite Model). The similar items results are generated from the image pool of ~10 million Mercari item listing.
The below figure describes the client-side (Android) process workflow:

Here are some of the similar image search results on the Demo Android application interface:

The feature extraction processing time for various Android devices are as follows:
| Android Devices | Avg. Feature Extraction Time (per image) |
|---|---|
| Google Pixel 3 | 0.15 sec |
| Google Pixel 2 | 0.21 sec |
| Asus Zenfone 5 | 0.28 sec |
| Moto G5s Plus | 0.65 sec |
The ranking of various Android devices performance on different machine learning tasks can be found here.
Future of Client-Side Computing
Client-side machine learning is an emerging field in the machine learning domain. Every technology comes with benefits coupled with certain challenges. As discussed earlier, client-side machine learning provides an edge over the server-side implementation with benefits including real-time offline inference, data privacy and reduction in server cost. However there are challenges in terms of model size-accuracy tradeoff, edge device’s configurations and ease in model version update. Therefore the above benefits and challenges are needed to be weighed in to choose between client-side or server-side machine learning implementation for your company or application. For example, if server cost of fifty dollars a day is a reasonable business tradeoff for your company then you should be using server-side whereas if there is high traffic at the server, then one should think of switching to client-side. Also for certain applications when you want to see inference on your personal photos but don’t want them to be shared to the server, client-side implementation could be beneficial.
Many services like Google Photos, Google Assistant, Nest and Shazam are already using client-side machine learning feature in their products[9, 10]. In the future, there would be a lot of improvements done to tackle the above-discussed challenges. With many modern tools such as TensorFlow Lite and active research carried on model size quantization to reduce accuracy-size tradeoff, applying client-side machine learning in everyday life at a large scale is becoming a possibility. In addition, this would narrow the gap between the high end and the low end mobile user experience for machine learning based product inferences.
References
- Samuel, Arthur L. “Some studies in machine learning using the game of checkers. II—Recent progress.” IBM Journal of research and development 11.6 (1967): 601-617.
- Silver, David, et al. “Mastering the game of Go with deep neural networks and tree search.” nature 529.7587 (2016): 484.
- https://google.github.io/flatbuffers/.
- https://developers.google.com/protocol-buffers/.
- Szegedy, Christian, et al. “Rethinking the inception architecture for computer vision.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
- Howard, Andrew G., et al. “Mobilenets: Efficient convolutional neural networks for mobile vision applications.” arXiv preprint arXiv:1704.04861 (2017).
- https://developer.android.com/ndk/guides/neuralnetworks.
- https://ai.googleblog.com/2018/04/mobilenetv2-next-generation-of-on.html.
- https://www.tensorflow.org/lite.
- https://www.tensorflow.org/about/case-studies/.



