Hi, my name is Rikuo Hasegawa and I am a participant of the mercari Summer Internship 2017 Machine Learning Course. I usually build plant factories or play with shaders in my free time. Prior to this internship, I only had about 3 days of machine learning experience so it’s a wonder that I was accepted, but I was able to complete my task thanks to the help of my mentor and everyone at mercari.
The task I worked on during the internship was cancel detection of transactions between users based on chat messages.
Framing the problem
Cancel detection is important for proactive support. Proactive support is a concept in customer support in which support is given proactively before trouble occurs, or in the early phases of trouble before the damage is too big. More specifically, we want to automatically detect trouble between users and intervene before there is too much damage. My task focuses on the first half, trouble detection.
The problem is defined as predicting whether a transaction will result in a cancellation based on the chat messages between users in the US version of the mercari app.
Solutions Explored
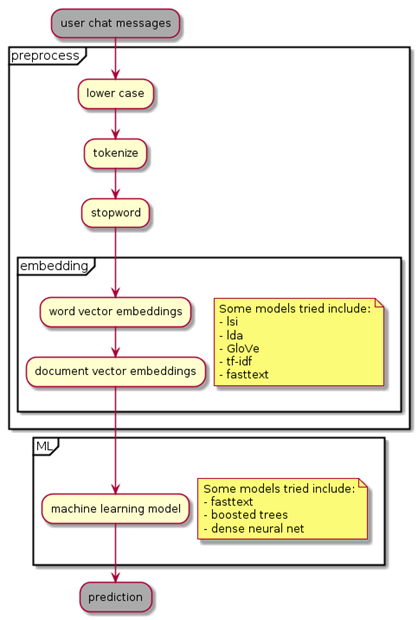
My approach to this problem is a fairly orthodox approach in natural language processing.

The original message text is preprocessed and sent through a word2vec algorithm to return a word embedding vector. The resulting vector is fed through a machine learning algorithm in order to predict whether a transaction will end in cancellation.
The key metric for validation was the precision for positive cancel detection. If the model decides that a transaction will result in cancellation, it should result in cancellation. Recall (the model should detect as many cancellations as possible) was of lesser priority because there is a limited amount of processing power that can be provided by customer support.
| process | example |
|---|---|
| Original string | ‘Hey have you received the item? :)’ |
| Lower Case | ‘hey have you received the item? :)’ |
| Tokenize | [‘hey’, ‘have’, ‘you’, ‘received’, ‘the’, ‘item’, ‘?’, ‘:’, ‘)’] |
| Remove Stopwords | [‘hey’, ‘received’, ‘item’, ‘?’, ‘:’, ‘)’] |
| word2vec | array([ 2.66015066e-03, 4.55169956e-03, -6.50415844e-05, 4.02189033e-03, 2.29045914e-03, -1.07180556e-03, 3.34109931e-03, -4.75122298e-04, -1.51061914e-04, … |
I kept the preprocessing the same, but changed the word embedding algorithm as well as the machine learning models.
The preprocessing was fairly straightforward. First, all characters are lowercased. Then, the message sentences/paragraphs are tokenized. Tokens are similar to words, but some words contain multiple tokens like the “do” and “n’t” in the word “don’t”. Then, common words in the english language are removed along with words that occur too infrequently.
After this preprocessing, the words are transformed in to word embedding vectors through some kind of word2vec algorithm.
The word2vec algorithms tried included fasttext1, tf-idf2, lsa 3, lda4, and GloVe5.
Regarding machine learning models, I tried a few different approaches as well.
Initially, I tried using Facebook’s fasttext algorithm because it creates its own word embeddings and can train a prediction model, providing a top down tool for baseline testing.
Initially, I used the provided supervised+predict command, but switched to using the predict_prob command for regression. This way, I can adjust the threshold to increase the precision.
fastText provided me with a precision of 86% with a recall of 6%. I then tried using gradient boosting in combination with some other word2vec algorithms.
| Feature | Precision | Coverage |
|---|---|---|
| lsi | 0.88 | 0.12 |
| lda | 0.86 | 0.01 |
| tfidf | 0.89 | 0.10 |
| glove | 0.85 | 0.07 |
As we can see, some embeddings did better than others. tf-idf or lsa seems to do about the same, with GloVe following behind. lda has similar precision to GloVe but has very low recall and also takes considerably longer. During this test, the GloVe embeddings were trained on the tokens from the preprocessing process described above.
At this point, my mentor and I decided to implement an API endpoint for the model so far.
From this point on, I decided to try the “deep learning” thing everyone is talking about.
I based my model off of https://github.com/bradleypallen/keras-quora-question-pairs and changed the input layer to be one end instead of two. The model keeps the precision of 88% and increases coverage to 14%.
Below is a simulated sample of the final model.
| speaker | msg | pred |
|---|---|---|
| guest | $100 for all that’s pictured? | 0.60 |
| host | Yes, for all! | 0.50 |
| guest | Sounds good. Thank you!!! | 0.37 |
| guest | Paid it, thanks! | 0.31 |
| host | Thank you will ship tomorrow | 0.13 |
| guest | Cool | 0.11 |
| guest | Have you shipped it? | 0.17 |
| guest | have you shipped it yet? | 0.20 |
| guest | Give me a tracking number, I’m cancelling | 0.85 |
| guest | Fraud seller | 0.92 |
Next steps in this work might include multiclass identification of various forms of trouble as well as making a model for earlier detection of trouble using other inputs like how reliable a seller is for shipping, how many times has a user cancelled orders in the past, etc.
Summary and Thoughts
If you’ve stuck around this far, thanks for bearing with me. If you can read Japanese, there are 6 other articles from the other Machine Learning Interns on the advanced work they’ve done.
This internship was one of the best experiences I’ve ever had. Everyone involved had a very high degree of technical skill, and a strong thirst for getting things done. However, there was no effort wasted in anything else aside from getting work done. Nobody gets upset that you arrived 30 minutes late, based on 性善説, a belief that anyone at mercari is fundamentally capable and will get the work done. There are people moving around on hoverboards and regardless of experience or age, rewards are given in return for proper work.
The motto “Go Bold” is used as a valid reason in decision making, which is very brave and only functions when everyone trusts each other.
This was the first summer internship for mercari, but I’ve been told they want to continue doing this next year so I highly recommend everyone to apply next year.



