はじめまして、メルカリで機械学習エンジニアとしてインターン中の@shidoです。
今回はメルカリ内部で使用する機械学習プロダクトにマルチモーダルモデルを用いることで、予測精度の向上に成功した話をご紹介いたします!
マルチモーダルとは
マルチモーダル(Multimodal)なデータは、「ひとつのデータに対する情報が複数(multi)の形式(mode)で存在しているデータ」と説明できます。
例えば動画配信サイトで配信されている動画には、映像・音声・説明文と、ひとつのビデオについて少なくとも3つの形式で情報が存在していると考えることが出来ます。
メルカリに出品されている商品について考えると、ひとつの商品について写真・説明文・値段など複数の形式で情報が存在しているので、これもまたマルチモーダルなデータといえます。
メルカリでの応用:不正出品検知
現在メルカリでは1日100万品以上が出品され、売れている商品の約半数は24時間以内に売れています。そのためトラブル・犯罪防止の観点から、不正な出品をなるべく早く検知し対処することは重要なタスクとなっています。
すべての商品を人手で確認することは難しいため、人工知能技術を活用し検知に役立てています。
人手で判断する場合は説明文や画像などを見て総合的に判断ができますが、人工知能でも同様に様々な情報から総合的に判断させることが目標となります。
今回は不正出品検知タスクにマルチモーダルモデルを利用して効果を確認していきますが、メルカリでは他にも様々な方面で機械学習を応用しております。
モデルの検証
実際には不正出品は複数の種類がありますが、そのうちの1つを検知するタスクでモデルの比較を行います。
データセットとして過去に事務局で不正と判断された/されていないものを使用します。
評価は予測のMean Average Precision (MAP)で行います。
1. ベースモデル
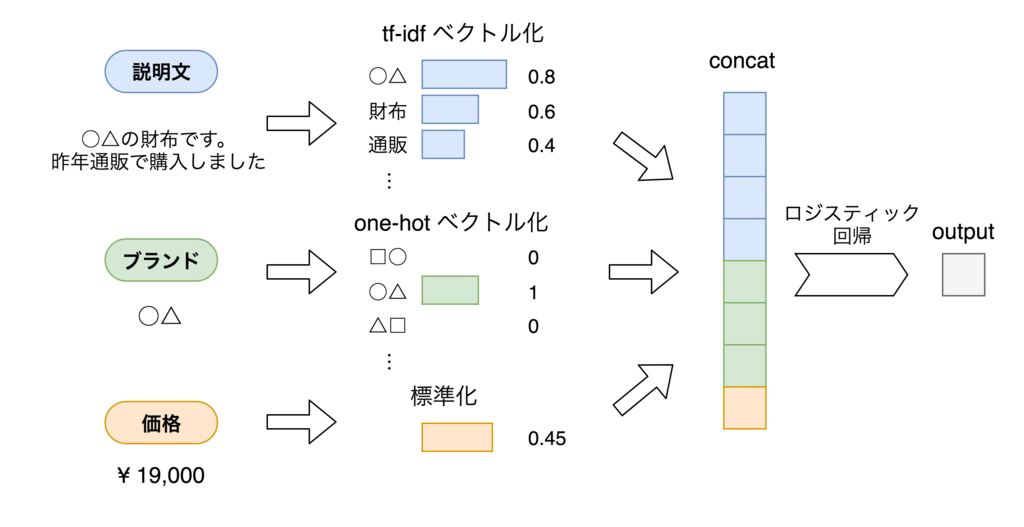
従来では、以下のような線形モデルを用いていました。

説明文(テキスト)・ブランド(カテゴリカルデータ)の特徴量抽出は、それぞれtf-idfベクトル化・one-hotベクトル化という方法で行っています。
こちらのモデルでは MAP: 0.7487 となり、これがベースラインになります。このモデルも説明文・ブランド・価格という情報を入力として使っているのでマルチモーダルなモデルと言えます。
この非常にシンプルな線形モデルから工夫を加えて改良を行っていきます。
2. 商品画像を用いたマルチモーダルモデル
次に、商品画像を特徴量に加えるモデルを試します。以下がモデルの概要です。

モデルの詳細
画像・テキストそれぞれの特徴量を抽出する部分と合成した特徴量から出力を得る部分にニューラルネットを用いることで、特徴量の抽出・合成・出力までを誤差逆伝播法を用いてend-to-endに学習することが出来ます。
特徴量を取得する手法として、テキストは多層パーセプトロン(MLP)、画像は畳み込みニューラルネットワーク(CNN)を使用します。
より画像の特徴を得やすくするために、CNNはinception-v3という一定の性能が保証されているモデルにImageNetと呼ばれる巨大なデータセットで分類タスクを学習させたもの(fine-tuneさせたもの)を利用します。
inception-v3を用いるため学習はGPUが必須となり、Tesla-V100のインスタンスで約36万アイテムの学習に5時間強かかります。
また推論にはCPUで500ms前後、GPUでその1/60ほどの時間がかかります。
ただし、トライアンドエラーを多く回すためDeepLearningフレームワークにKerasを用いており、実用の際はpure Tensorflowの利用など様々な高速化を用います。
特徴量合成について
また、このようなモデルでは特徴量合成によくconcatenate=連結する手法が取られますが、ここに工夫の余地があります。例えば、Multimodal Classification for Analysing Social Mediaでは特徴量合成にmax-poolingを用いることでconcatenateした場合よりも精度が向上することを述べています。
筆者による実験では、特徴量をconcatenateするだけでは分類に効かない特徴量に引きずられかえって性能が悪くなってしまうデータセットがありました。しかしそのようなデータセットでもmax-poolingを用いるだけで性能の悪化を抑止する事ができたため、max-poolingが特徴量の取捨選択に有効に働いているのではないかと考えています。
結果
このモデルでは特徴量合成に
concatenateを用いた場合 MAP: 0.7690
max-poolingを用いた場合 MAP: 0.7704
となり、画像が不正出品の検知に有効であること、max-poolingが特徴量合成の手法としてconcatenateより優れていることが確認できました。
3. カテゴリカルデータ・連続値データの追加
ベースモデルではone-hot encodingを用いてカテゴリカルデータであるブランドIDを、また連続地である価格も標準化して特徴量として用いていました。これらの情報も入力として利用するためモデルを変更します。
以下がモデルの概要となります。

モデルの詳細
前項のモデルのように、「各入力から固定長の特徴量を抽出してmax-poolingで合成すると性能が上がる」という仮説が成立すれば、固定長の特徴ベクトルへと変換できるようなニューラルネットがあればどんな入力でも追加することができ、今後別のモデルを作る際にも方針が立てやすくなりますし、何より見た目がきれいになります。笑
そういうわけで、ブランドID等も固定長の特徴ベクトルに落とすニューラルネットを用いています。
またテキストの特徴抽出にCNNによるものを加えます。CNNを追加することでMLPとは異なる分類に役立つ特徴量を抽出できると考えました。
MLPは1-gramを用いており文章内の単語の組み合わせによく反応できるはずですが、否定語+動詞のような時系列情報は取得できません。一方CNNは連続した否定語+動詞の出現などに敏感に反応することが出来るはずです。
また学習・推論の時間についてはモデルの中でinception-v3が飛び抜けて重いのでテキスト+画像のモデルと大きな差はありません。
特徴量合成について
max-poolingによる特徴量合成を用いることで性能の向上が望めることを先述しましたが、ブランドID等を追加した時点で画像+テキストのモデルから精度が向上しない(ほぼ同等の性能しか出ない)という結果になりました。
私達はこれが各入力から得られる特徴量のスケールが一致しないことに原因があると考え、各入力の特徴量抽出後に標準化を行う層を追加しました。
ここで標準化とは得られた特徴ベクトルを長さ1の超球面上に写像する操作を指します。
これによりさらなる性能の向上と学習の安定化が可能となりました。
標準化層を追加した際、optimizerにモーメント付きSGDを用いると収束に非常に時間がかかるため今回はoptimizerにAdamを用いて収束の高速化を図っています。
結果
標準化層の導入により、画像+テキストのモデルから
ブランドID、カテゴリ、価格の追加で MAP: 0.7870
更にCNNによるテキストの特徴量抽出の追加で MAP: 0.7924
を達成しました。
まとめ
今回はマルチモーダルモデルについていくつか検証と工夫を行い、メルカリが持つデータに対しても有効であることを確かめました。
今回の検証では、紹介した特徴量合成手法を用いることで入力とするモダリティを追加すればするほど精度が向上するという結果が得られました。
もしこのスキームが成立するのであれば、マルチモーダルモデルの作成が容易になりますし、(今回テキストを二種類の方法で特徴抽出しているように)モダリティがひとつの場合でも同じモデル又は違うモデルを特徴抽出に用いたアンサンブル学習等に応用できるのではないかと思います。
以下は今回の検証でのMAPの変化をまとめたものです。

最後に
近年は安価にGPU等の計算資源が確保できるようになり、画像認識・音声認識・自然言語処理など様々な分野で深層学習が台頭し目覚ましい成果が挙げられています。
これらの個々の分野で挙げられた成果の融合、つまりマルチモーダルモデルという部分の研究はまだまだこれからといった印象を受けますが、実践的な場面でも有効であることが確かめられました。
今回は単純な分類タスクでの検証でしたが、今後マルチモーダルモデル周りの研究開発は盛んに行われていくのではないでしょうか。
インターンではメルカリのようにひとつの大きなプロダクトの一部に携わる経験、メルカリの持つ特殊なデータでとことん実用に向けた研究開発を行う経験などここでしかできないことが数多くありました。短期間でしたが一定の成長を得られたと感じています。
メルカリでは通年でインターンの募集をしていますので、興味のある方は応募してみてはいかがでしょうか。

