これはMercari Advent Calendar 2017 の2日目の記事です。
昨日は @stanaka の分散ファイルシステムはブロックチェーンの夢を見るか でした。
今回は@Hmj_kd が、メルカリの機械学習の取り組みや機械学習エンジニアの今年行ってきた活動のいくつかをご紹介したいと思います。
以下、一部にて機械学習をMLと略します。
この1年間で機械学習で取り組んだこと
私が入社したのは2017/01で、社内では二人目の機械学習エンジニアでした。
その当時は
にあるように、プロダクトにMLに関するものはありませんでした。
現在は、チーム全体でマネージャも含めて約10人ほどの組織になり、活発に実験や開発が行われています。
いくつかを列挙しますと
- 商品出品時の価格推定とサジェスト - 一部カテゴリについて商品タグの推定 - 商品出品時のカテゴリや出品タイトルのサジェスト
などがあり、ML関係のリポジトリだけで約10個ほどが作られてきました。
こちらについては
で概要をご紹介しています。
機械学習のプロダクト開発は、実装してテスト、デプロイだけではなく
- どういった課題がありどう解決されたいのか?
- 解決策として機械学習のモデルを適用するのがベストで速いか?
- モデルを適用したとして、どのくらい精度がでるのか? などをトライアルで実験する
- 仮にデプロイされてお客さまに提供された後、本当に事業上に関係する数値に改善がみられるのか?
など、実装の前後にプロセスがあり、一つの課題解決でみても息の長いプロジェクトとなります。
そういった中でも、一年間で数個のML関係の機能が、実際にお客さまの目に触れる部分などにリリースされることは、
私の今までの経験でもありませんでした。
運用を始めてでてきた課題
一年間でいくつかのMLのプロダクトをリリースできたのは、関係するプロジェクトメンバーのプロフェッショナルな仕事はもちろんのこと、
各機械学習エンジニアが他社で実際に開発や運用の経験があること、が大きく影響していると私は思っています。
一方で、いくつかのプロダクトを運用をするにあたり課題や問題がみえてきました。ご紹介をしたいと思います。
- ローカル環境のMeCabと本番環境のMeCabが違う問題
- 誰かのデプロイによって、誰かのモデルがdegradeしちゃった問題
- 開発環境の構築に時間がかかる問題
- 大規模なモデルの管理とデプロイをどうするか問題
- 毎朝稼動しているモデルの精度を気にしながら、別のモデルの実験に集中しないといけない
などなど。初歩的なミスによるものありましたが、一般的に機械学習を導入する現場で登場する課題かと思います。
メルカリの機械学習を支える技術
機械学習の導入初期は、インフラやデプロイ等いくつかの問題を解決しながら、モデルをデプロイしていくことになるかと思いますが、
長期的にみれば機械学習エンジニアはモデル作りに集中できることがベストだと私は考えています。
そこで、現在メルカリの機械学習チームでは、機械学習のプロダクトを徐々にmicroservices化しています。
またその基盤としてはこちらで紹介されているように、Kubernetesへのコンテナアプリケーションで稼動させてデプロイにはSpinnaker を採用されています。
コンテナアプリケーションやmicroservices化を受け入れることは、機械学習的な視点でみると下記のような利点がありました。
- コンテナにより開発環境の構築の容易さやバージョン違い等に悩まされないこと
- 機械学習チームがそれぞれ独立して安心、安全にデプロイを行えること
- 継続的な学習とデプロイをしやすくなったこと(後述)
事例 : Spinnaker の cron による機械学習モデルの精度監視と学習の実行
モデルの精度監視と学習を行う理由ですが、機械学習モデルはタスクに依りますが、時間が経つにつれて精度が落ちてきます。
たとえば、商品名から商品カテゴリを推定するケースなどを考えると、メルカリでは新しい商品が出品されていきますので、学習時には存在しなかった商品については推定することができません。
そのような理由から、本番で稼動しているモデルの精度は常に気になるところです。
ですが、現時点では数個のモデルですが、組織が拡大していく中で、今後稼動するモデルも増えることが見込まれます。
場合によっては数十個となる可能性もあり、毎朝モデルの精度チェックの定期タスクが大変になると思いました。
そのような思いから、実験的ではありますが、SpinnakerのPipelineを組み合わせて、精度チェックのjobと学習のjob, そしてデプロイを組み合わせることを行いました。社内ではこのアーキテクチャをゼータとよんでいます。
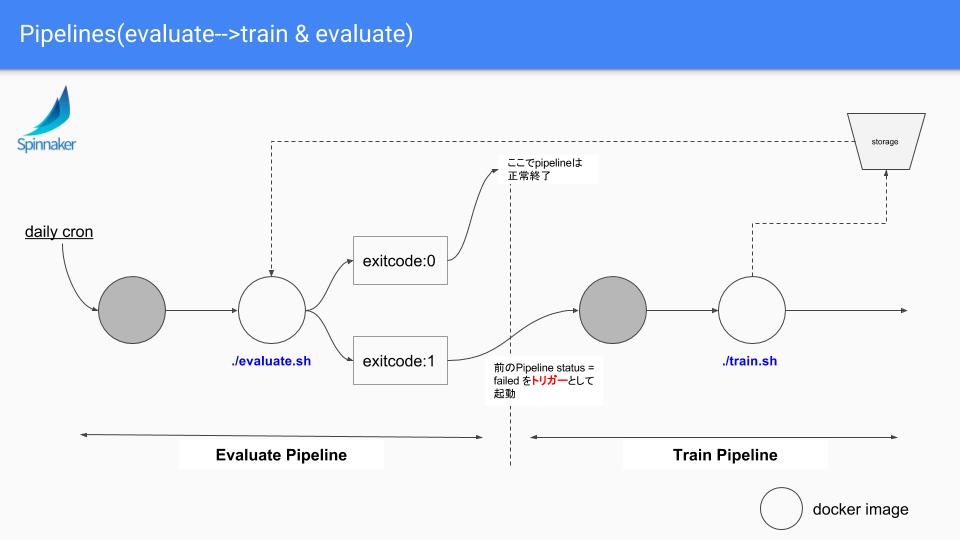
下記はそのPipelineのイメージ図となります。

前提としてSupervised learning(教師あり学習)のタスクでtraining setはデータベースに溜まっていていつでも新しいものを取得できる想定です。
フローとしては
- cronによるトリガーでPipelineを起動します
- evaluate の job にて、最新のモデルと、評価用のデータセットを取得して、そのタスク毎に設定されたスコアの計算を行います。ここでスコアが下がっていなけばPipelineはここで終了します。
- もし下がっていた場合、学習用のデータセットを取得して、学習と評価を行います。この時、それでもスコアがあがらなければ、アラートが通知されます。
- 下がっていない場合は、学習済みのモデルとアプリケーションコードを内包したDocker imageをbuildし直して、Spinnakerにより安心、安全にデプロイさせます。
となり、スコアがあがらないときを除けば、機械が勝手にモデルの質を担保した状態を保ってくれます。
これから
本記事では機械学習の取り組みや機械学習エンジニアの今年行ってきた活動のいくつかをご紹介しました。
Spinnakerなどによりデプロイや基盤がどんどんスケールすることを感じています。
次にスケールさせたいのは、機械学習のモデル設計の部分です。強化学習の応用*1でモデルの設計や最適化ができるようになれば、このあたりもスケールしていくのではと思っています。
プロダクト以外ですと、
のように、画像認識に関する会議や自然言語処理の学会などへの参加しており、
今後も画像認識・機械学習の取り組みを積極的に行っていきたいと思います。
また,8月には初のサマーインターンシップを実施が実施されました。
機械学習/自然言語処理分野のエンジニアやインターンを積極的に募集しておりますので、ご興味ありましたらご連絡いただければと思います。
Software Engineer, Machine Learning/Natural Language Processing
3日目の明日はmhidakaです。




