メルカリのバックエンドを支える SRE(Site Reliability Engineering) チームに最近加わりました @syu_cream です。
本記事では KPI に関わる数値を計算してレポートを生成する集計システムの刷新に取り組んでいる話を紹介します。
現在は刷新の途中であり、集計項目ベースでいうと 1/3 ほどの実装が済み、現行システムと刷新後のシステムの一部を並行稼動させている状態です。
背景
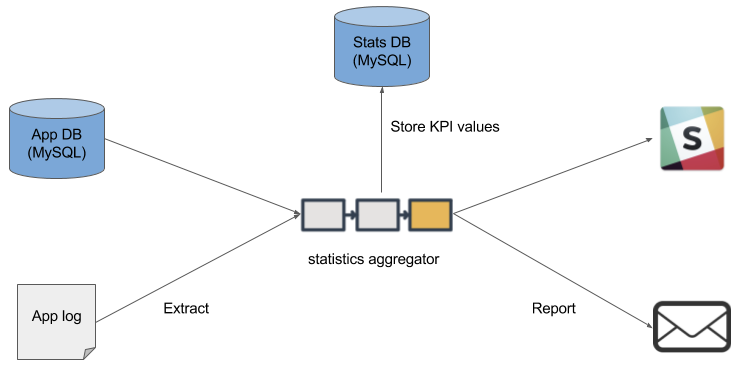
メルカリではアプリケーションのログファイルやデータベースから、 DAU(Daily Active Users) などの KPI に関する様々な数値を集計するためのシステムを稼働させています。
この集計システムは毎日 Slack やメールにて KPI のサマリーレポートを送信し、全社員が数値を閲覧し、日々プロダクトの傾向を意識することを可能にしています。
集計システムの動作イメージは下図のようになります。

また以前当ブログで紹介したとおり、メルカリではプロダクトの分析・改善のために様々なツールを用いています。
この集計システムでは日次の集計結果を MySQL に格納しており、これらの分析ツールからの数値の参照を可能にしています。
しかしこの集計システムですが、創業間もないころから稼働しており近頃ではメンテナンスもあまりされていないレガシーなシステムとなってきました。
加えて、US, UK事業展開のため以前は想定されていなかったロジックなどを追加していった都合、実装が複雑になり機能拡張や運用が困難になっていました。
更に集計処理はシングルスレッドで実行されておりCPU パワーを使い切れていない、メモリの使用量が多いなどのマシンリソース使用面での問題点も顕著になってきました。
これらの課題を払拭するため、今回集計システムの刷新に踏み切った次第です。
改修方針
改修方針の概略ですが下図のようになります。

まず集計した数値の格納先ストレージですが、集計システムのもつ役割を減らすため、現状 MySQL を利用しているところを BigQuery に置き換えることにしました。
メルカリでは既にアプリケーションログなどさまざまなデータを BigQuery に格納している都合、 BigQuery にアクセスできればデータの利活用ができるという状況を強化することができるとも考えています。
これに合わせて集計処理の再実装は、今回 Cloud Dataflow を用いることにしました。
Cloud Dataflow は ETL(Extract Transform Load) 処理を行うためのマネージドサービスであり、 Apache Beam を基盤にしています。
これを利用することでジョブの実行状況が明確になり、前述したマシンリソースの問題もオフロードできるというメリットが生じます。
Cloud Dataflow 以外の選択肢として Spark を利用可能なマネージドサービスである Cloud Dataproc などの利用を検討したのですが、 Cloud Dataflow のオートスケール機能やクラスタ・インスタンス管理が不要な点、パイプラインが可視化可能な点、 Beam SDK だけで BigQuery など Google Cloud Platform のサービスと連携可能である点などが決め手となり今回採用しました。
また Cloud Dataflow で処理するデータソースを予め BigQuery にアップロードするため Embulk とそのプラグインである embulk-output-bigquery を利用しています。
Cloud Dataflow による集計処理の実装
Cloud Dataflow で実行する集計処理の実装方針について少しブレークダウンします。
Cloud Dataflow が基盤にしている Apache Beam では Java SDK と Python SDK が提供されています。
基本的にこれらを利用して Java もしくは Python で集計処理を実装していくことになります。
しかしながら Java SDK はコレクション操作関数を apply() でチェーンしていく
やや風変わりなコードを書かなければならず、 Python SDK は Java SDK と比較して一部機能がサポートされていないなど気になる点が存在します。
そこで今回は Spotify 製 Scala 実装ライブラリ Scio を利用することにしました。
Scio を利用することで以下のような恩恵を得られます。
- Scala のコレクション操作ほぼそのままに、 Apache Beam のデータ変換ロジックを実装できる
- BigQuery のスキーマ定義からクラス生成をしてくれる Type safe BigQuery を利用できる
- Scio で追加されたいくつかの便利関数が利用できる(キーごとに値の合計値を算出する
sumByKey()など)
Scio を利用して Cloud Dataflow で実行するコードを実装する話はわたしの個人ブログにも記載しておりますので、サンプルコードや動作イメージなどを掴みたい方は参照してみていただければと思います。
Scio を利用して、例えば DAU の集計は以下のように実装しています。(計算に使用している値、集計ロジックはブログ掲載向けに一部修正しており、オリジナルそのままではありません)
map など Scala でよくあるコレクション操作のような見た目を維持しつつ、簡潔なコードで集計処理が実装できていると思われます。
object DauPipeline { def process(sc: ScioContext, day: String) { sc .typedBigQuery[Users](Users.query.format(day)) .map(u => getType(u.id)) .countByValue .map{ case(utype, num) => DauRow(day.toLong, utype, num) } .saveAsTypedBigQuery(BIGQUERY_TABLE_BASE + "dau", WRITE_APPEND, CREATE_IF_NEEDED) } }
Cloud Dataflow のジョブ一覧画面で閲覧できる実行結果の例を一部切り抜いたものが下図になります。
Scala + Scio で書かれたデータ変換ロジックがどのようなフローになるのか自動で製図されています。

現状と今後
現在は日本リージョンにおける Slack で KPI レポートを送信するのに最低限必要な、現行システムでカバーしているうち 1/3 ほどの集計項目の Cloud Dataflow 版実装を済ませ、現行の集計処理と並行して試験的に稼働させている状態です。
現行の集計処理が cron で日次実行されるのですが、最後に追加する形で試験集計と Slack 通知を行っています。
# 従来の集計処理 ... # NOTE: run Dataflow for experiment ./embulk/dataflow/jobs.sh ./dataflow/jobs.sh ./daily_slack_post_from_bq.sh
集計処理に要する時間ですが、現行集計システムが Slack でのレポートに必要なデータを計算し終わるまで最近の実績値で約 8 分掛かっているのですが、 Cloud Dataflow での集計は約 5 分未満で終了できています。
Cloud Dataflow はオートスケールの他に明示的にワーカー数を指定することもできるので、今後集計処理を追加していくあるいは更に早く集計結果を出したい要望が出てきた際に柔軟に対応できるものと思われます。
今後ですが、集計処理を並行稼動させつつ Cloud Dataflow 版に問題が発生しないかを観察しながら、 US, UK リージョンでの対応と集計ロジックの実装を行っていく予定です。
また今後ワークフローが複雑になるようであれば Apache Airflow などワークフローエンジンの導入を検討しようと思っています。
おわりに
今回紹介した集計システムの刷新は取り組みたい課題のごく一部です。
メルカリではコードをバリバリ書いてプロダクトの改善に貢献していける仲間を募集中です!もしご興味を持っていただけましたら、以下のページをご参照いただければ幸いです。




